Работа с СУБД в Python
Что такое базы данных?
База данных - набор сведений, хранящихся некоторым упорядоченным способом. Можно сравнить базу данных со шкафом, в котором хранятся документы. Иными словами, база данных - это хранилище данных. Сами по себе базы данных не представляли бы интереса, если бы не было систем управления базами данных (СУБД).
Система управления базами данных - это совокупность языковых и программных средств, которая осуществляет доступ к данным, позволяет их создавать, менять и удалять, обеспечивает безопасность данных и т.д. В общем СУБД - это система, позволяющая создавать базы данных и манипулировать сведениями из них. А осуществляет этот доступ к данным СУБД посредством специального языка - SQL.
Реляционные базы данных
Преимущества
Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
- Наличие чёткой структуры.
- Соответствие базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
Вот признаки проектов, для которых идеально подойдут SQL-базы:
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
Язык SQL
Первая реляционная база данных родилась в подразделении IBM Research в начале 70-х гг. В то время языки запросов основывались на сложной математической логике и не менее сложной нотации. Два свежеиспеченных кандидата наук, Дональд Чемберлин и Раймонд Бойс, впечатлились реляционной моделью данных, но при этом увидели, что используемый язык запросов будет препятствовать ее распространению. Они решили разработать новый язык запросов, который, по их словам, будет «более удобным для пользователей, не прошедших курс математики или компьютерного программирования».
В результате появился SQL, впервые представленный миру в 1974 году, и в следующие несколько десятилетий он станет очень популярным. Поскольку в отрасли ПО обосновались реляционные базы данных (например, System R, Ingres, DB2, Oracle, SQL Server, PostgreSQL, MySQL и многие другие), SQL широко распространился как язык взаимодействия с БД и стал общепринятым в экосистеме, которая становилась все более конкурентной.
С ростом сети Интернет разработчики ПО обнаружили, что реляционные базы данных не могут справиться с такой нагрузкой. Затем два новых интернет-гиганта совершили прорыв — разработали собственные распределенные нереляционные системы, предназначенные для решения проблемы с возрастающими объемами данных: MapReduce (публикация 2004 г.) и Bigtable (публикация 2006 г.) от компании Google и Dynamo (публикация 2007 г.) от компании Amazon. Упав на благодатную почву, опубликованные статьи дали хороший урожай нереляционных баз данных: Hadoop (на основе статьи по MapReduce, 2006 г.), Cassandra (авторы вдохновлялись статьями по Bigtable и Dynamo, 2008 г.), MongoDB (2009 г.) и др. Новые системы были написаны преимущественно с чистого листа, поэтому они тоже не использовали SQL, что привело к росту «движения NoSQL».
Творение компаний Google и Amazon распространилось, похоже, гораздо шире, чем предполагали сами авторы. И понятно, почему так случилось: NoSQL-системы были в новинку; они обещали масштабирование и мощь; казалось, что это — быстрый путь к успешной разработке. И тут начали вылезать проблемы.
Вскоре разработчики обнаружили, что отсутствие SQL на самом деле существенно ограничивает. У каждой базы данных NoSQL был собственный уникальный язык запросов, а это означало следующее: нужно было изучать больше языков (и обучать своих коллег); подключать эти базы данных к приложениям было сложнее, что заставляло писать тонны неустойчивого связующего кода; отсутствие сторонней экосистемы — а значит, компаниям приходилось разрабатывать собственные инструменты для визуализации и работы с БД.
Языки NoSQL только появились, поэтому их нельзя было назвать полными и завершенными: в реляционных БД, к примеру, многие годы работали над добавлением в SQL необходимых функций.
Разработчики ПО стали понемногу начали возвращаться к SQL.
NoSQL
NoSQL – коротко о главном NoSQL базы данных: понимаем суть
Термин NoSQL. Есть две трактовки: одна старая, другая новая. Оригинальная — это NoSQL, т.е., вообще, никакого SQL-а нет, а есть какой-то другой механизм, для работы с этой базой данных. И более новая трактовка — это «Not only SQL» — это не только SQL, т.е. может быть SQL, но есть что-то помимо.
- Не используется SQL (точнее, не использовался)
- Неструктурированные (schemaless)— в отдельной строке или документе можно добавить произвольное поле без предварительного декларативного изменения структуры всей таблицы. Таким образом, если появляется необходимость поменять модель данных, то единственное достаточное действие — отразить изменение в коде приложения.
- Приятное следствие отсутствия схемы — эффективность работы с разреженными (sparse) данными. Если в одном документе есть поле date_published, а во втором — нет, значит никакого пустого поля date_published для второго создано не будет.
- Представление данных в виде агрегатов (aggregates). В отличие от реляционной модели, которая сохраняет логическую бизнес-сущность приложения в различные физические таблицы в целях нормализации, NoSQL хранилища оперируют с этими сущностями как с целостными объектами.
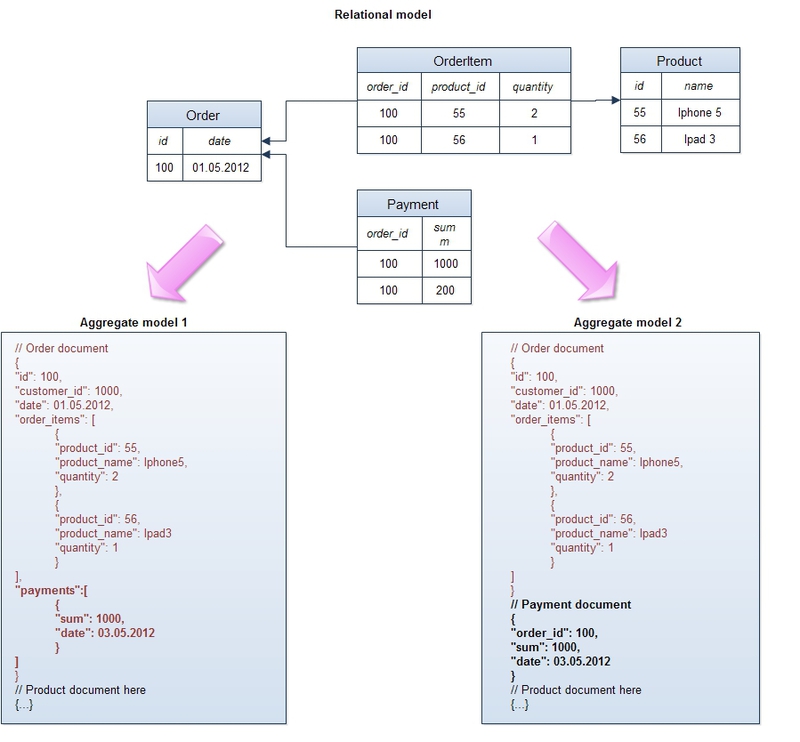
- Слабые ACID свойства. Долгое время консистентность (consistency) данных была “священной коровой” для архитекторов и разработчиков. Все реляционные базы обеспечивали тот или иной уровень изоляции — либо за счет блокировок при изменении и блокирующего чтения, либо за счет undo-логов. С приходом огромных массивов информации и распределенных систем стало ясно, что обеспечить для них транзакционность набора операций с одной стороны и получить высокую доступность и быстрое время отклика с другой — невозможно. Эти требования уже давно неактуальны. NoSQL БД заменили принцип consistency на eventual consistency — в грубом переводе на русский это означает, если не было конфликтующих записей, то когда-нибудь попозже кластер придет в согласованное состояние, при этом не дается каких-то гарантий по конкретным промежуткам — когда-нибудь.
- Распределенные системы, без совместно используемых ресурсов (share nothing). Вертикальная масштабирумость.
Теорема CAP
Распределенная система не может одновременно обладать более чем двумя из следующих трех характеристик — это доступность (availability), согласованность (consistency) и устойчивость к разрывам сети (partition tolerance).
Виды БД по типам данных
Список NoSQL-БД. Доступность — это если у нас есть распределенная система, и мы обращаемся на любой ее узел и гарантированно получаем ответ. Если мы запрашиваем какие-то данные, то можем получить устаревшие версии этих данных, но мы получим данные, а не ошибку, или мы могли бы не достучаться до этого сервера. Если мы получили данные, то система доступна.
В противоположность этому система может быть согласована. Что означает согласованность? Если мы на одном узле записали какие-то данные и спустя некоторое время на другом узле пытаемся прочитать эти данные, если система согласована, мы получим новую версию данных, которую мы записали в другом месте.
Хранилище пар «ключ-значение» (Redis, Memcashed)
Минимальный интерфейс для такой базы данных состоит всего из 3-х операций — get, set и delete.
Документ-ориентированная база данных (MongoDB)
СУБД, специально предназначенная для хранения иерархических структур данных (документов). В основе документоориентированных СУБД лежат документные хранилища, имеющие структуру дерева. API для поиска позволяет находить по запросу документы и части документов. В отличие от хранилищ типа ключ-значение, выборка по запросу к документному хранилищу может содержать части большого количества документов без полной загрузки этих документов в оперативную память.
Колоночные базы данных (HBase, Cassandra, Vertica)
Их сильная сторона в способности хранить большое количество данных с большим количеством атрибутов. Они немного по-другому хранят данные, нежели, например, реляционные базы данных — реляционки хранят по строкам, т.е. все атрибуты одной строки лежат рядом. Эти делают наоборот, они хранят отдельно колонки. Есть файл — в нем хранятся все поля данной колонки из всех 3-х млрд. записей, хранятся все рядом. Соответственно, другая колонка хранится в другом файле. За счет этого они могут применять улучшенное сжатие за счет использования информации о типе данных колонки. Также это может ускорять запросы, если, нам, например, нужны 3 колонки из 300, то нам не обязательно грузить остальные 297.
Графовые базы данных (Neo4j)
Предназначены для обработки графов — набора вершин, соединенных ребрами. Например, социальные сети — это один большой граф. Дорожная сеть и прокладка маршрутов, рекомендация товаров.
Сила этих баз данных в том, что за счет своей специализации они могут эффективно выполнять всякие операции над графами, но также в силу той же специализации они не сильно распространены.
Мультимодельные базы данных
Приемущества
- Нереляционные базы лучше поддаются масштабированию, оно линейно. Линейная масштабируемость — это когда мы путем увеличения ресурсов кластера получаем пропорциональное увеличение характеристик кластера. Удвоили количество серверов — получили в два раза больше производительность:
- Н* Можно хранить большое количество данных
- Н* Высокая доступность — мы разносим нашу базу данных по нескольким датацентрам: в Америке, в Европе, Японии, если вдруг в какой-то из них бьет молния, и он исчезает, то мы можем писать в другие датацентры, и доступная база данных нам это позволит.
- Во многих случаях позволяют разработчику отражать сущности предметной области на сущности БД без введения дополнительных сущностей, которые приходится вводить в реляционных СУБД.
- Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
- Быстрая разработка. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
Недостатки
- Накладные расходы в коде приложения при смене модели данных
- Отсутствие всевозможных ограничений со стороны базы (not null, unique, check constraint и т.д.)
- Сложности в понимании и контроле структуры данных при параллельной работе с базой разных проектов (отсутствуют какие-либо словари на стороне базы)
- Необходимость изучения нового api запросов для каждой новой СУБД (см. Я не буду учить твой Garbage Query Language)
Вот свойства проектов, для которых подойдёт что-то из сферы NoSQL:
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.
Проектирование
Главное правило проектирования структуры данных в NoSQL базах — она должна подчиняться требованиям приложения и быть максимально оптимизированной под наиболее частые запросы. Если платежи регулярно извлекаются вместе с заказом — имеет смысл их включать в общий объект, если же многие запросы работают только с платежами — значит, лучше их вынести в отдельную сущность.
Когда не стоит использовать
-
Почему SQL одерживает верх над NoSQL, и к чему это приведет в будущем
-
Когда ваши данные по своей природе реляционны.
-
Когда невозможно заранее спроектировать модель использования (или лично вы не умеете проектировать).
- Недостаточная или избыточная нормализация
Практика
Создание схемы данных в SQLite
Для создания реляционной БД необходимо вначале описать схему, в которой определим будут определены таблицы с колонками, типами данных колонок и отношениями между ними.
cursor.execute(""" CREATE TABLE Authors( id TEXT PRIMARY KEY UNIQUE NOT NULL, name TEXT, region TEXT, gender TEXT, age INTEGER, city TEXT, stage TEXT )""") cursor.execute(""" CREATE TABLE Texts( id INTEGER PRIMARY KEY UNIQUE NOT NULL, raw TEXT, lemm TEXT, url TEXT, datetime TEXT, author TEXT, title TEXT, stage TEXT, FOREIGN KEY (author) REFERENCES Authors (id) ON DELETE CASCADE ON UPDATE CASCADE )""") cursor.execute(""" CREATE TABLE Ethnonyms( id TEXT PRIMARY KEY UNIQUE NOT NULL )""") cursor.execute(""" CREATE TABLE Assessors( id TEXT PRIMARY KEY UNIQUE NOT NULL )""") cursor.execute(""" CREATE TABLE Ethnonyms_Texts( text_id INTEGER NOT NULL, ethnonym_id TEXT NOT NULL, PRIMARY KEY(ethnonym_id, text_id), FOREIGN KEY(ethnonym_id) REFERENCES Ethnonyms(id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY(text_id) REFERENCES Texts(id) ON DELETE CASCADE ON UPDATE CASCADE )""") cursor.execute(""" CREATE TABLE Assessors_Ethnonyms_Texts( text_id INTEGER NOT NULL, ethnonym_id TEXT NOT NULL, assessor_id TEXT NOT NULL, about_whole_nation_recoded INTEGER, encourage_aggression_meaning INTEGER, is_ethicity_aggressor_meaning INTEGER, is_ethicity_dangerous_meaning INTEGER, is_ethicity_superior_meaning INTEGER, opinion_about_ethnonym_recoded INTEGER, represent_ethicity_meaning INTEGER, FOREIGN KEY (text_id) REFERENCES Texts (id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (assessor_id) REFERENCES Assessors (id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (ethnonym_id) REFERENCES Ethnonyms (id) ON DELETE CASCADE ON UPDATE CASCADE, PRIMARY KEY (text_id, ethnonym_id, assessor_id) )""") cursor.execute(""" CREATE TABLE IF NOT EXISTS Assessors_Texts( text_id INTEGER NOT NULL, assessor_id TEXT NOT NULL, do_text_make_sense INTEGER, has_eth_conflict INTEGER, has_ethnonym INTEGER, has_pos_eth_interaction INTEGER, has_topic_culture INTEGER, has_topic_daily_routine INTEGER, has_topic_economics INTEGER, has_topic_ethicity INTEGER, has_topic_history INTEGER, has_topic_humour INTEGER, has_topic_migration INTEGER, has_topic_other INTEGER, has_topic_politics INTEGER, has_topic_religion INTEGER, has_topic_society INTEGER, is_text_neg INTEGER, is_text_positive INTEGER, FOREIGN KEY (text_id) REFERENCES Texts (id) ON DELETE CASCADE ON UPDATE CASCADE, FOREIGN KEY (assessor_id) REFERENCES Assessors (id) ON DELETE CASCADE ON UPDATE CASCADE, PRIMARY KEY (text_id, assessor_id) )""")
Для облегчения понимания:
- Руководство по проектированию реляционных баз данных (1-3 часть из 15) [перевод]
- Полиморфные связи для самых маленьких
А для тех, кто хочет окунуться в теории реляционных баз полностью — добро пожаловать на курс на Степике.
В результате получаем такую структуру
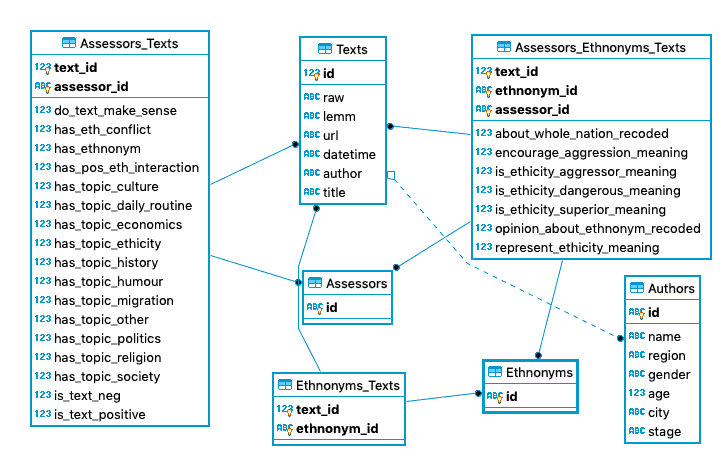 Создано при помощи Dbeaver
Создано при помощи Dbeaver
MongoDB
Не требуется.
Pandas DataFrame
Не требуется.
Подключение к СУБД
SQLite
### Импортируем библиотеку, соответствующую типу нашей базы данных import sqlite3 connection = sqlite3.connect('data/ethno.db') connection.execute("PRAGMA foreign_keys = ON") cursor = connection.cursor()
В конце необходимо будет выполнить connection.commit() чтобы воплотить изменения и connection.close() чтобы закрыть соединение.
MongoDB
mongodb://<dbuser>:<dbpassword>@ds024548.mlab.com:24548/hse
from pymongo import MongoClient import urllib.parse username = urllib.parse.quote_plus('student') password = urllib.parse.quote_plus('student1') connection_url = 'mongodb://{}:{}@ds024548.mlab.com:24548/hse'.format(username, password) client = MongoClient(connection_url) db = client.hse collection = db.test
Pandas DataFrame
import pandas as pd
df = pd.read_msgpack("data/ethno_df.msgpack")
Создание выборки данных
Давайте сделаем выборку 10-и текстов из каждой системы хранения — SQLite, MongoDB и Pandas Dataframe. Отобразим всю информацию об авторах текстов, сам текст и время его написания. Причем, зададим условия, что нам нужны только лишь тексты пользователей из Москвы и СПб возраста старше 24 лет.
SQLite
Базовый синтаксис такой
SELECT column1, column2 ..., columnN FROM table_name WHERE condition;
Подробнее здесь:

sql_query = ''' SELECT Texts.datetime, Texts.raw, Authors.region, Authors.age, Authors.gender FROM Texts LEFT JOIN Authors ON Authors.id = Texts.author WHERE Authors.region IN ('Москва', 'Санкт-Петербург') AND Authors.age >= 25 LIMIT 10 '''
cursor.execute(sql_query).fetchone() # fetchall() для всех записей
'Холокост с обратной стороны. Литовский политик призвал Израиль платить литовцам за спасение евреев » Москва - Третий Рим',
'Москва',
55,
'Женщина')
pd.read_sql(sql=sql_query, con=connection)
| datetime | raw | region | age | gender | |
|---|---|---|---|---|---|
| 0 | 2014-01-07 15:48:00 | Холокост с обратной стороны. Литовский политик... | Москва | 55 | Женщина |
| 1 | 2014-02-27 17:37:55 | Степан, бот ты все не угомонишься? как то вас ... | Санкт-Петербург | 36 | Мужчина |
| 2 | 2014-02-28 02:07:42 | Сергей, в Крыму уже находятся 76-я десантно-шт... | Санкт-Петербург | 28 | Мужчина |
| 3 | 2014-05-05 23:33:46 | Друзья всем советую смотреть <b>кыргыз</b> кин... | Москва | 1945 | None |
| 4 | 2014-06-06 15:38:00 | Инкубатор <b>пархатых</b> это Россия. По нашей... | Москва | 66 | Мужчина |
| 5 | 2014-12-02 15:48:04 | нормально все ходит. я через банк фк открытие ... | Санкт-Петербург | 28 | Мужчина |
| 6 | 2014-12-11 17:06:12 | В США полицейский застрелил безоружного <b>афр... | Москва | 33 | Женщина |
| 7 | 2015-01-12 21:06:57 | Симферополь.Памятник братьям Айвазовским - Ива... | Санкт-Петербург | 1945 | Мужчина |
| 8 | 2015-01-12 21:06:57 | Симферополь.Памятник братьям Айвазовским - Ива... | Санкт-Петербург | 1945 | Мужчина |
| 9 | 2015-01-15 16:31:18 | [[id65482402|Эдик], что ты несешь, дурашка? Ес... | Санкт-Петербург | 31 | Мужчина |
MongoDB
Операторы запросов: https://docs.mongodb.com/manual/reference/operator/query/
for doc in collection.find({ "author.region" : {"$in": ["Москва", "Санкт-Петербург"]}, "author.age": {"$gte": 25} }, {"author": 1, "datetime": 1, "raw": 1}).limit(10): print(doc)
{'_id': ObjectId('5be13353732ce962ac47d3a9'), 'raw': 'Степан, бот ты все не угомонишься? как то вас плохо готовят. Может расскажешь нам про еще про довольных индейцев, аборигенов Австралии, африканских туземцев которым Запад принес свою цивилизацию? У нас вот в России все национальности равны, и якуты, буряты и т.д читать и писать умеют, причем даже на своем языке.Может расскажешь последним 500 австралийцам, какая Россия тюрьма народов.', 'datetime': '2014-02-27 17:37:55', 'author': {'id': 'id3756501', 'region': 'Санкт-Петербург', 'city': 'Санкт-Петербург', 'gender': 'Мужчина', 'age': 36.0}}
{'_id': ObjectId('5be13353732ce962ac47d3aa'), 'raw': 'Сергей, в Крыму уже находятся 76-я десантно-штурмовая дивизия ВДВ, 31-я десантно штурмовая бригада ВДВ и бригада спецназа ГРУ. По твоему они зря деньги на топливо тратили? В Крыму живут русские, они в любом случае за Россию проголосуют. Наша задача просто проконтролировать, чтобы в Крым инородцы не сунулись до голосования', 'datetime': '2014-02-28 02:07:42', 'author': {'id': 'id333966', 'region': 'Санкт-Петербург', 'city': 'Санкт-Петербург', 'gender': 'Мужчина', 'age': 28.0}}
{'_id': ObjectId('5be13355732ce962ac47d3c6'), 'raw': 'Друзья всем советую смотреть кыргыз кино \\ кыз жигит\\', 'datetime': '2014-05-05 23:33:46', 'author': {'id': 'hApPy aNgEl', 'region': 'Москва', 'city': 'Москва', 'gender': None, 'age': 1945.0}}
{'_id': ObjectId('5be13355732ce962ac47d3cf'), 'raw': 'Инкубатор пархатых это Россия. По нашей глупости и безмозглости, они здесь плодятся и живут...как глисты, в организме здорового человека. Стоит принять слабительное (Сталин)...и их понесло на обетованную и не только...потом они возвращаются. А мы все хиреем и хиреем. Спасибо за интернет. Многие поймут многое. А поймут, значит перекос будет исправлен. Хочется верить в это...перед смертью.', 'datetime': '2014-06-06 15:38:00', 'author': {'id': 'id201470753', 'region': 'Москва', 'city': 'Москва', 'gender': 'Мужчина', 'age': 66.0}}
{'_id': ObjectId('5be13358732ce962ac47d3fa'), 'raw': 'нормально все ходит. я через банк фк открытие (номос) работаю. это косяки с реорганизацией… открытия и хантов', 'datetime': '2014-12-02 15:48:04', 'author': {'id': 'atialloy', 'region': 'Санкт-Петербург', 'city': 'Санкт-Петербург', 'gender': 'Мужчина', 'age': 28.0}}
{'_id': ObjectId('5be13359732ce962ac47d3fe'), 'raw': 'В США полицейский застрелил безоружного афроамериканца\r
В конце ноября в США прошли массовые акции протеста после того, как коллегия присяжных вынесла оправдательный вердикт по делу Даррена Уилсона, полицейского из Фергюсона, который в августе застрелил безоружного афроамериканца Майкла Брауна.', 'datetime': '2014-12-11 17:06:12', 'author': {'id': 'id240088822', 'region': 'Москва', 'city': 'Москва', 'gender': 'Женщина', 'age': 33.0}}
{'_id': ObjectId('5be13359732ce962ac47d408'), 'raw': 'Симферополь.Памятник братьям Айвазовским - Ивану и Габриэлю находится в сквере имени Дыбенко рядом с площадью Советской.\\nАйвазовский Иван Константинович был русским живописцем, почетным членом Петербургской академии художеств. В 1880-м году он основал в Феодосии картинную галерею, которую впоследствии со всеми своими произведениями завещал городу.\\nСтарший брат Ивана Константиновича – Габриэль Константинович Айвазовский был известным просветителем армянского народа, педагогом, ученым-востоковедом и талантливейшим писателем.\\nПамятник был установлен по инициативе армянского национального общества Крыма «Луис».\\nК стыду своему', 'datetime': '2015-01-12 21:06:57', 'author': {'id': 'Fil26', 'region': 'Санкт-Петербург', 'city': 'Санкт-Петербург', 'gender': 'Мужчина', 'age': 1945.0}}
{'_id': ObjectId('5be1335a732ce962ac47d409'), 'raw': 'Симферополь.Памятник братьям Айвазовским - Ивану и Габриэлю находится в сквере имени Дыбенко рядом с площадью Советской.\\nАйвазовский Иван Константинович был русским живописцем, почетным членом Петербургской академии художеств. В 1880-м году он основал в Феодосии картинную галерею, которую впоследствии со всеми своими произведениями завещал городу.\\nСтарший брат Ивана Константиновича – Габриэль Константинович Айвазовский был известным просветителем армянского народа, педагогом, ученым-востоковедом и талантливейшим писателем.\\nПамятник был установлен по инициативе армянского национального общества Крыма «Луис».\\nК стыду своему не знал, что Айвазовский армянин и ч', 'datetime': '2015-01-12 21:06:57', 'author': {'id': 'Fil26', 'region': 'Санкт-Петербург', 'city': 'Санкт-Петербург', 'gender': 'Мужчина', 'age': 1945.0}}
{'_id': ObjectId('5be1335a732ce962ac47d40d'), 'raw': '[[id65482402|Эдик], что ты несешь, дурашка? Если в японскую деревню подселить одного зулуса и двух таджиков, Япония от этого многонациональной страной не станет, как бы тебе этого не хотелось в твоих влажных либерашкомечтах. Воевали в подавляющем большинстве русские, украинцы, беларусы и татары. Потому что каквказцы, крымские татары и среднеазиаты были любителями немножко поубивать русских за старые обидки за противоположную сторону при первой же возможности. Хотя чаще всего они просто уклонялись, да и в подавляющем большинстве к службе были непригодны. Или ты считаешь, что узбекский хлебороб, подкармливающий армию, внес соразмерный вклад в победу с ребятами из Сталинграда? И запомни, сосунок, это на наших плечах живут "гастрики", а не наоборот. Хотя лично тебе я искренне желаю получить в пузо толерантный гасторбайтерский нож за твой говноайфон. Накорми несчастных азиатов лично, мразота тупорылая. Покажи нам пример дружбы народов!', 'datetime': '2015-01-15 16:31:18', 'author': {'id': 'id58547406', 'region': 'Санкт-Петербург', 'city': 'Санкт-Петербург', 'gender': 'Мужчина', 'age': 31.0}}
Pandas DF
# наишите сами
Удаление данных
Удалим из базы записи, которые связаны с текстами про русских (это слово может быть прилагательным и указывать не только на этноним).
SQlite
Да практически также, как и выборка, только SELECT меняем на DELETE и не указываем колонки.
sql_remove = ''' DELETE FROM Ethnonyms WHERE id = 'русский' ''' cursor.execute(sql_remove) # fetchall() для всех записей
cursor.execute("SELECT * FROM Ethnonyms_Texts WHERE ethnonym_id = 'русский'").fetchall() # connection.commit() # пока не будет выполнена эта строка, изменения не будут внесены.
Обращайте внимание на возможнось каскадного удаления (см. Руководство по проектированию реляционных баз данных. Каскадное удаление данных). Оно нужно, чтобы сохранить ссылочную целостность.
Ссылочная целостность может нарушиться) в следующих случаях:
- обновляется внешний ключ (ссылка на идентификатор в таблице категорий) в строке-потомке.
- добавляется новая строка-потомок. Добавляем новую вещь, а она не принадлежит ни одной категории.
- удаление строки-предка.
- обновление первичного ключа в строке-предке.
Средства поддержания ссылочной целостности SQL позволяют обрабатывать указанные случаи.
MongoDB
collection.delete_many(query) # где query — это такой же запрос как с find # делать это мы не будет, посколько это сможет сделать только один человек
Pandas DataFrame
#
Изменение данных
SQlite
MongoDB
Pandas DataFrame
Полнотекстовый поиск
В SQL
Есть два способа осуществить поиск по строке в SQLite. Первый — медленный, но простой. Второй — быстрый, но немного сложнее.
Начнём в первого — можно использовать оператор LIKE, который найдёт строки, похожие на шаблон. Он регистрозависимый.
cursor.execute("SELECT * FROM Texts WHERE raw LIKE '%Вы че%'").fetchall()
'Да нам-то вы нах не вперлись. Извините. У нас земли с перебором. На 100 поколений хватит. В Вас проблема. Не обижали бы вы Русских, проблем бы не было бы. Первый закон после переворота какой Рада приняла? Об отмене статуса Русского языка. Ваши западенцы понаехали на Донбасс мгновенно. Вы че? Вы, действительно, думаете, что Русские - рабы? Да вы заебетесь пизды огребаться! Не на тех нарвались! Это Россия.',
None,
'http://vk.com/wall217372490_1879',
'2015-02-28 17:53:23',
'id181542797',
None)]
Также в SQLite существует возможность выстрого полнотекстового поиска, но для этого надо немного поплясать с бубном.
Во-первых, необходимо создать виртуальную FTS-таблицу. Назовём её fts_table:
cursor.execute("CREATE VIRTUAL TABLE fts_table USING fts5 ( id, raw )");
Во-вторых, необходимо наполнить её значениями. В данном случае, мы просто скопируем в неё колонки id, raw из таблицы Texts:
cursor.execute("INSERT INTO fts_table SELECT id, raw FROM Texts");
И только затем мы можем производить поиск при помощи ключевого слова MATCH:
cursor.execute("SELECT * FROM fts_table WHERE raw MATCH 'вы че'").fetchall()
'Да нам-то вы нах не вперлись. Извините. У нас земли с перебором. На 100 поколений хватит. В Вас проблема. Не обижали бы вы Русских, проблем бы не было бы. Первый закон после переворота какой Рада приняла? Об отмене статуса Русского языка. Ваши западенцы понаехали на Донбасс мгновенно. Вы че? Вы, действительно, думаете, что Русские - рабы? Да вы заебетесь пизды огребаться! Не на тех нарвались! Это Россия.')]
Уффф... Это только начало, другие БД предоставляют более богатые возможности и более сложный синтаксис. Изучать его мы, конечно, не будем.
В MongoDB
Тут всё немного проще благодаря оператору $text. Единственная неочевидная вещь, которую требуется сделать — это создать текстовый индекс на том поле, по которому вы будете искать. Ну хоть не таблицу.
collection.create_index([('raw', 'text')])
repr(collection.find_one({ "$text" : { "$search" : "вы че" }})["raw"])
collection.find({ "$text" : { "$search" : "вы че" }}).count()
"""Entry point for launching an IPython kernel.
В Pandas
также существую обширные возможности для работы с текстом.
df[df.raw.str.contains("Вы че")].raw
839 Да нам-то вы нах не вперлись. Извините. У нас ...
1114 Да нам-то вы нах не вперлись. Извините. У нас ...
1214 Да нам-то вы нах не вперлись. Извините. У нас ...
2334 Да нам-то вы нах не вперлись. Извините. У нас ...
2512 Да нам-то вы нах не вперлись. Извините. У нас ...
Name: raw, dtype: object
df.raw.str.contains("Вы че").sum()
Самостоятельная
Сделайте следующие задания в каждой системе хранения данных:
- Загрузите 10 первых записей с информацией об авторах из каждой системы (поле "author" в mongodb, таблица "author" в SQLite, колонки author, region, city, gender, age в DF).
- Найдите тексты, в которых упоминаются этнические группы 'татары' и 'русские'. Сколько таких текстов?
- В Pandas и SQL найте все тексты, в написанные мужчинами младше 20 лет. Кто в них чаще упоминается? В SQL используйте GROUP BY
sql_group = ''' SELECT Authors.region, COUNT(*) AS `num` FROM Texts LEFT JOIN Authors ON Authors.id = Texts.author WHERE Authors.region IN ('Москва', 'Санкт-Петербург') AND Authors.age >= 25 GROUP BY Authors.region '''
Существует немало других функций для работы с аггрегированными данными помимо COUNT.
- Создайте из SQLite базы таблицу, которая будет похожа таковую из Pandas DataFrame. В ней должна содержаться вообще вся информация — какой текст написал какой автор, какие этнические
connection.close()
Комментарии