Введение в рекоммендательные системы
Это первая статья из планируемого цикла, в котором я разберу эволюцию алгоритмов, используемых для построения content-based рекомендательных систем, основанных на факторизационных машинах. Именно над реализацией такой задачи я сейчас работаю в Мвидео-Эльдорадо, поэтому отчасти эти статьи будут писаться по мотивам рабочих заметок. В качестве основного инструмента для реализации алгоритмов будет использоваться фреймворк для нейронных сетей PyTorch. Предварительное содержание цикла следующее: мы начнём с построения простой регрессионной модели, затем перейдём к логистической регресии, от неё к множественной регрессии с факторами, моделирующими взаимодействие признаков, далее решим проблему огромного числа весов в этих моделях при помощи факторизационных машин [1] с различными надстройками (FFM [2], например), а продолжим, наверное, гибридными моделями, где факторизационные машины будут соседствовать с глубокими нейронными сетями: Wide-And-Deep [3], Deep and Cross [4], DeepFM [5], xDeepFM [6], HoAFM [7] — на сколько хватит терпения.
Однако, прежде, чем углубиться в детали, необходимо разобраться с понятием рекомендательной системы. Прежде всего следует понимать, что под этим названием скрывается не какая-то особая группа алгоритмов, какой являются, например, классификаторы или регрессии, алгоритмы с учителем и без — рекомендательные системы объединены только лишь задачей, которую можно сформулировать как заполнение таблицы, строки которой будут представлять пользователи, а столбцы — рекомендуемые сущности (фильмы, товары, музыка и т.п.). Ячейки этой матрицы, соответственно, будут говорить о том, сколько раз каждый пользователь взаимодействовал с каждой сущностью. В общем-то, почти любой алгоритм можно использовать для решения задачи рекомендации. Чаще всего это будут классификаторы, но так же могут быть и регрессионные модели. Пожалуй, только группу алогоритмов, основанных на коллаборативной фильтрации можно считать характерными именно для рекомендательных систем.

Вообще, довольно непросто выделить основные виды рекомендательных систем, и разные авторы подходят к этой задаче по-разному. Тут можно сослаться на товарища Aggarwal, специализирующемся на написании обзорных пособий по алгоритмам машинного обучения, который не обошёл своим вниманием и рекомендательные системы [8]. Он выделяет пять основных групп таких алгоритмов.
Алгоритмы коллаборативной фильтрации, основанные на поиске соседей (neighborhood-based collaborative filtering)
... которые делятся на user-based и item-based. Для их создания необходимо всего лишь одна описанная выше матрица пользователи-сущности. Далее необходимо заполнить пустые значения в этой матрице, найдя для каждого пользователя наиболее похожих «соседей» и заполнив пропуски конкретного пользователя, взвешенно усредняя рейтинги «соседей» (user-based) или найдя похожие сущности для каждой другой сущности и рекомендовать пользователям сущности, похожие на тех, с которыми они уже контактировали (item-based). В общем-то всё различие между этими двумя подходами состоит только в том, на какой матрице применять методы заполнения пропусков — исходной или транспонированной.
Отличительным признаком этого типа алгоритмов является способность выставлять оценки, основываясь лишь на признаках отдельного наблюдения. Другими словами, для того, чтобы составить рекомендации для некоторого пользователя, нам нужно знать предпочтения похожих на него других пользователей, и не нужно обучать никакие веса на всём наборе данных, потому что и самого этапа обучения тут нет, как нет и целевой переменной, содержащей истинные значения. Точно также, например, работает алгоритм классификации по k ближайшим соседям, который располагает все объекты в некотором пространстве, а затем приваивает неизвестным объекта тот класс, который имеют большинство из k ближайших к ним соседей.
Алгоритмы коллаборативной фильтрации, основанные на моделях
Вторая большая выделенная Aggarwal группа — это алгоритмы коллаборативной фильтрации, основанные на моделях (Model-Based Collaborative Filtering). В целом, они похожи на алгоритмы, описанные выше, с тем лишь исключением, что последние тезисы из последнего абзаца к ним не применимы. К этой групп относятся многие модели, которые у всех на слуху — решающие деревья, нейронные сети, регрессии, машины опорных векторов и так далее. Соответственно, их применение подразумевает обучение параметров, для чего необходимо разделение данных на обучающую и тестовую выборки, а также выделение целевых и независимых переменных.
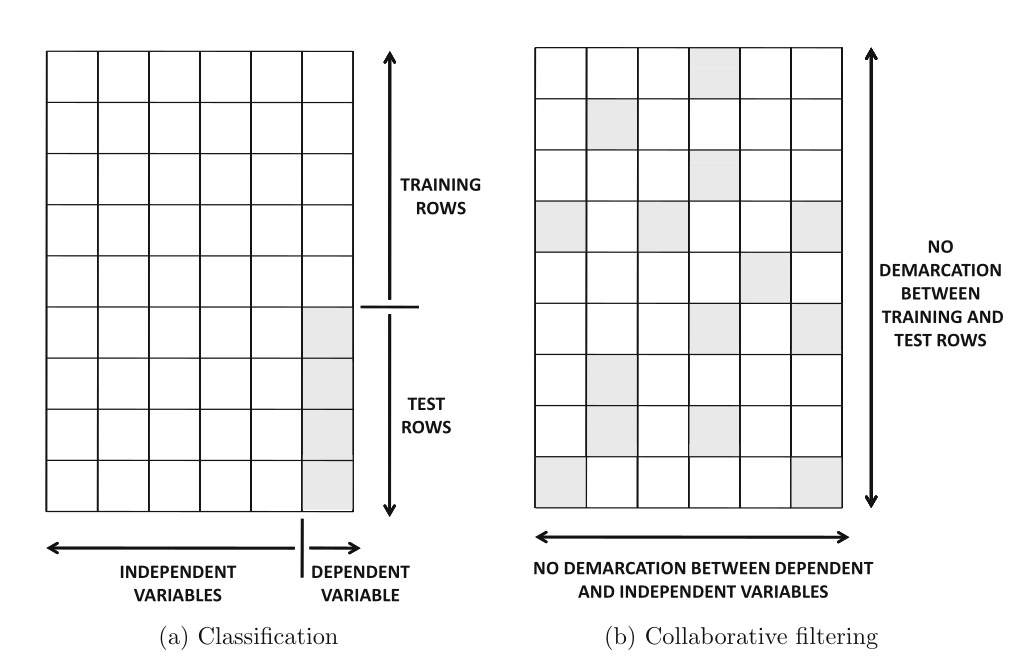
Обычно алгоритмы коллаборативной фильтрации, основанные на моделях, работают лучше, чем предыдущие, поскольку они учитывают скрытые закономерности в данных, причём делают это быстрее и с меньшем потреблением памяти. Это происходит потому, что для их работы достаточно единожды подобрать нужные веса, которые затем будут применяться к новым данным, в то время как основанные на соседях алгоритмы вынуждены искать соседей для каждого наблюдения среди всех остальных — такой подход плохо масштабируется.
Рекомендательные системы, основанные на содержании
Два предыдущих подхода используют для предсказания лишь корреляции между пользователями и сущностями и не учитывают близость их аттрибутов. Например, часто мужчинам и женщинам нравятся разные фильмы, а жанр фильма скорее всего повлияет на то, каким пользователям он понравится, а каким нет, поэтому хорошо было бы учесть эти и многие другие атрибуты в рекомендательной системе. Именно это и делают, рекомендательные системы, основанные на содержании (content-based recommender systems).
В отличии о предыдущих подходов прогнозируя предпочтения пользователя они обычно почти не используют информацию о предпочтениях других пользователей, принимая во внимания лишь его атрибуты и историю взаимодействия с сущностями. Эта характеристика делает их особенно подходящими в ситуациях, когда у нас недостаточно информации о взаимодействии других пользователей с сущностями, зато имеются обширные данных о самих пользователях. Так, например, обстоят дела в предсказании категории следующей покупки в ритейле, где клиенты в среднем совершают очень небольшое количество покупок, поэтому сложно найти похожих людей. Правда, с этим же совойством рекомендательных систем, основанных на содержании, есть проблема, заключающаяся в том, что, обучившись на истории пользователя, они склонны рекомендовать сущности, с которыми он уже взаимодействовал, в вот с новыми рекомендациями у них обычно бывают проблемы. Именно такой тип рекомендательных систем мы будем рассматривать в дальнейшем.
Рекомендательные системы, основанные на знаниях (knowledge-based recommender systems)
Этот тип рекомендательных систем рекомендует объекты не только на основе их характеристик, но и с учётом правил и ограничений. Например, нет смысла рекомендовать купить товар, который отсутствует в продаже. Некоторые выделяют этот тип рекомендательных систем в отдельную категорию, другие включают его в группу рекомендательных систем, основанных на содержании, ведь ограничения и правила можно рассматривать как ещё один вид характеристик пользвоателя или товара.
Графовые рекомендательные системы
Довольно интересный вид рекомендательных систем, который товарищ Aggarwal обошёл внианием. О них я немного рассуждал в записи «Cегментация при помощи графов». Его суть заключается в построении графа, вершинами которого являются или объектры рекомендаций или пользователи, котороым эти рекомендации предназначены, с дальнейшим предсказанием связей между ними.
Гибридные рекомендательные системы (hybrid recommender systems)
Тут всё просто — в эту группу входят все возможные смешанные модели разных видов, соединенные по схеме бустинга, блендинга, беггинга и вообще как угодно.
Далее мы будем рассматривать рекомендательные системы, основанные на содержании, причём в основном те их них, которые основаны на модели линейной регрессии в том или ином виде.
Литература
- Juan, Y., Zhuang, Y., Chin, W.-S., & Lin, C.-J. (2016). Field-aware Factorization Machines for CTR Prediction. Proceedings of the 10th ACM Conference on Recommender Systems, 43–50. https://doi.org/10.1145/2959100.2959134
Комментарии