Сегментация при помощи графов
Говоря о видах рекомендательных систем, обычно выделяют два основных типа таких моделей — рекомендательные системы, основанные на коллаборативной фильтрации или системы, основанные на содержании. При этом часто упускают ещё один крайне интересную разновидность рекомендательных систем, которая часто показывает результаты, не уступающие популярным нынче нейронным сетям [1].
Фактически, эта разновидность рекомендательных систем представляет собой адаптацию графовых методов, давно используемых в других сферах, например в социальных науках, под новую задачу. Обычно эти методы применяются для 1) визуализации структуры социальных сетей, 2) нахождения самых важных её членов, например узлов с наибольшим количеством связей с другими узлами (говоря в других терминах — с наивысшей центральностью) или через которые проходит наибольшее количество кратчайших путей (такие узлы называются брокерами), 3) а также для выделения меньших подсообществ внутри основной исследуемой группы. В социальных науках, понятное дело, в роли узлов чаще всего выступают люди в сообществах или слова в текстах. В одном из исследований, в котором я принимал участие, в роли узлов выступали тэги, присвоенные постам в instagram, а связью между парами узлов устанавливалась в случае их наличия у одного и того же поста [2].
Адаптация этих методов для задачи рекомендаций происходит довольно просто и естественно, если взять за узлы в сети принять товарные категории и проводить между ними связи (рёбра) в случае, если они встречаются среди покупок одного человека. Если какая-то пара категорий встречается более, чем у двух человек, то присваиваем связи между данной парой узлов больший вес, который в самом просто случае будет соответствовать количеству людей, у которых встречается эта пара категорий.
А далее — всё как раньше. Если необходимо сегментировать товарные категории — применяем алгоритмы выделения сообществ, если хотим рекомендовать пользователю какую-то категорию — используем, например, алгоритм случайного блуждания [3], как делают в одноклассниках для рекомендаций групп [4].
Рассмотрим, как это работает на конкретной задаче выделения товарных сегментов и отнесения к ним пользователей. То есть мы хотим разбить наши товары на небольшие кучки на основе совместных покупок, а затем рекомендовать каждую кучку определённому пользователю. Сегодня займёмся первой частью этой задачи — сегментацией.
За исходные данные возьмём связи между категориями покупок, записанные в формате списка рёбер — каждая строка будет представлять ребро графа и его вес, т.е. количество пользователей, у которых встречалась данная пара категорий. В SQL запрос, возвращающий нужные данные, может выглядеть примерно так:
SELECT t1.grp AS cat1 , t2.grp AS cat2 , COUNT(*) AS weight FROM filtered_bills t1 INNER JOIN filtered_bills t2 ON t1.client = t2.client AND t1.grp <> t2.grp GROUP BY t1.grp, t2.grp
Итак, мы загрузили данные в нужном формате:
import networkx as nx import pandas as pd from cdlib import algorithms # df_edges был загружен ранее df_edges.head(3)
| cat1 | cat2 | weight | |
|---|---|---|---|
| 0 | LED-4K UHD телевизор 56 - 65"_middle | Кронштейн для ТВ фиксированный_middle | 1670 |
| 1 | LED-4K UHD телевизор 56 - 65"_middle | Фотобумага для принтера_low | 157 |
| 2 | LED-4K UHD телевизор 56 - 65"_middle | Картридж для кофемашин_middle | 84 |
Теперь на основе этих данных создадим граф. Для работы с графами в python используются два основных пакета — networkx и python-igraph. Первый написан на python, из-за чего он не слишком подходит для больших графов, но зато имеет понятный интерфейс и развитую инфраструктуру вспомогательных библиотек. Второй является обёрткой над сишной библиотекой, поэтому легче переваривает большие объёмы данных, но менее удобен для проведения исследований. Я выберу первый вариант.
g = nx.from_pandas_edgelist( df_edges, source="cat1", target="cat2", edge_attr=["weight"] ) g.number_of_nodes(), g.number_of_edges()
Тут нас поджидает проблема — почти каждая категория была хотя бы один раз куплена с любой другой. Это означает, что для кластеризации нам нужно или использовать алгоритмы, поддерживащие установку веса рёбер, или придётся тем или иным образом отсекать лишние связи. Уменьшение количеста ребёр также будет необходимо для визуализации полученного графа, поскольку отрисовка всех 2.28 млн ребер сделает картинку нечитаемой.
Однако, и тот и другой способ в моём случае приводили к образованию небольшого числа очень крупных сообществ и большого числа сообществ с небольшим количеством, а часто и одним членом. К тому же, если выбран путь удаления ребер, не так просто определить, сколько ребер нужно удалять. Я пробовал оставлять топ ребёр для каждого узла, пробовал удалять рёбра, вес которых менее -ого процентиля, но к хорошим результатам это не приводило.
Тут на помощь приходит инструмент, который последние несколько лет пихают куда ни попадя, поскольку очень часто его использование позволяет улучшить результаты работы практически любых моделей — речь идёт о...
Word2vec для создания графов
О w2v написано очень много, поэтому просто сошлюсь на статью [5], с которой всё началось, и скажу лишь, что этот метод позволяет представить любые объекты, которые встречаются вместе (слова в предложении или категории покупок у одного человека) в виде вектора некоторой размерности. При обучении таких векторов учитывается в контексте каких других ближайших объектов встречается данный. Такое представление позволяет делать множество прикольных штук, но для нас важнее, что для двух векторов одинаковой размерности очень легко посчитать меру сходства.
Для создание w2v модели я буду использовать Gensim, а сходство посчитаю при помощи относительной косинусной меры, которая изначально была придумана для определения синонимов [6] и рассчитывается почти так же, как обычная, за тем лишь исключением, что её значение для пары объектов , делится на сумму косинусных мер между и самыми близкими к нему другими объектами. Из этого следует, что пара объектов со значением относительной косинусной меры более более близки, чем обекты из топ в среднем. Опираясь на эту идею, я буду удалять ребро между соотвествующими вершинами графа, если его вес меньше этого числа.
Таким образом, векторизация объектов через word2vec позволяет лучше учесть контекст взаимодействия, а использование относительной косинусной меры для определения веса связи и отсечение связей с весом менее позволяет оставить только самые значимые рёбра в графе.
Для работы с word2vec необходимо подготовить данные в формате списка списков. В нашем случае это будет список пользователей, в котором каждый пользователь будет представлен списком категорий.
from gensim.corpora import Dictionary from gensim.models import Word2Vec, WordEmbeddingSimilarityIndex # если нужно быстро посчитать матрицу обычных косинусных расстояний from gensim.similarities import SoftCosineSimilarity, SparseTermSimilarityMatrix from itertools import combinations relative_cosine_topn = 10 # пробуйте разные значения dictionary = Dictionary(docs) # обучаем w2v, параметры size подберите опытным путём w2v_model = Word2Vec(docs, size=20, window=2) relative_cosine_weights = [] for w1, w2 in combinations(w2v_model.wv.vocab.keys(), 2): relative_cosine_weights.append(( w1, w2, w2v_model.wv.relative_cosine_similarity( w1, w2, topn=relative_cosine_topn ) )) df_relative_cosine = pd.DataFrame( relative_cosine_weights, columns=["cat1", "cat2", "weight"] ) # отсекаем лишние связи df_relative_cosine = df_relative_cosine[ df_relative_cosine["weight"] >= 1/relative_cosine_topn ] # создаём объект графа при помощи networkx g = nx.from_pandas_edgelist( df_relative_cosine, source="cat1", target="cat2", edge_attr=["weight"] ) g.number_of_nodes(), g.number_of_edges()
Это далеко не единственный способ заэмбеддить графы. Обозор других, часто более хитроумных и специфичных способов смотрите в статье Graph Embedding Techniques, Applications, and Performance: A Survey [7].
Выделение сообществ
Существует множество алгоритмов выделения сообществ в структуре сети, но по моему опыту стабильно хорошие результаты по качеству и скорости показывает Лувиановский алгоритм, впервые представленный в 2008 году [8], но уже завоевавший огромную популярность. Для работы с сообществами я буду использовать библиотеку CDlib, где, конечно, имеется реализация этого метода, как и множества других [9].
communities = algorithms.louvain(g, weight='weight', resolution=0.05) pd.DataFrame.from_records([ (len(c), ", ".join(c)) for c in communities.communities ], columns=["cnt", "nodes"])[10:13]
| cnt | nodes | |
|---|---|---|
| 10 | 13 | Прибор для ухода за лицом, Массажер для тела, Электрогриль, Аксессуар для гриля, Угольный гриль, Прибор для ухода за ногами, Маникюрный набор, Прибор для чистки и массажа лица, Насадка для прибора по уходу за ногами, Массажер для ног, Фотоэпилятор, Массажная ванночка для ног, Массажная подушка |
| 11 | 13 | Крышка, Сковорода, Кастрюля, Сотейник, Сковорода вок, Кастрюля (антипригарное покрытие), Набор посуды (антипригарное покрытие), Набор кухонных ножей, Сковорода гриль, Набор посуды, Ковш, Набор посуды (нержавейка), Набор посуды (Jamie Oliver) |
| 12 | 13 | PSP ассортимент 2, Экран для видеопроектора, Виниловая пластинка, Проигрыватель виниловых дисков, Мультимедийный проигрыватель, Видеопроектор для домашнего кинотеатра, Видеопроектор мультимедийный, Подвес универсальный для видеопроектора, Контроллер для DJ, Комплекты для блогеров, Наушники для D... |
Получившиеся кластеры превосходят решения, полученные без использования word2vec — распределение количества элементов в них гораздо более ровное, а метрики более высокие. Кстати о метриках — их тоже можно посчитать при помощи CDlib. Например, метрика под названием модулярность Ньмана-Гирвана показывает разницу между между реальной долей связей внутри сообществ в общем количестве связей и ожидаемой долей таких связей в случае графа с таким же количеством вершин, ребер и распределением весов этих рёбер. Отличие нового графа в том, что связи и их веса присваиваются случайным образом. Следовательно, чем больше данная метрика, тем менее случайна и более определена структура сообществ в данном графе.
from cdlib.evaluation import newman_girvan_modularity newman_girvan_modularity(g, communities)
Визуализация
После уменьшения количества связей в графе мы можем построить его понятную визуализацию. Для этого можно воспользоваться встроенными в CDlib функциями (выглядит страшно, настраивается c трудом), запариться с plot.ly (настраиваемо, красиво, интерактивно, но требует больше усилий и довольно сильно тормозит) или нарисовать граф в Gephi — эдаком Экселе для графов. Последний вариант подходит как для быстрого прототипирования, так и для создания полноценных визуализаций — его я и выберу.
Если установить размер узла в соответсвии с его центральностью и цветом обозначить принадлежность к кластеру, то визуализация графа товарных категорий и выделенных на нём сообществ может выглядеть примерно так:
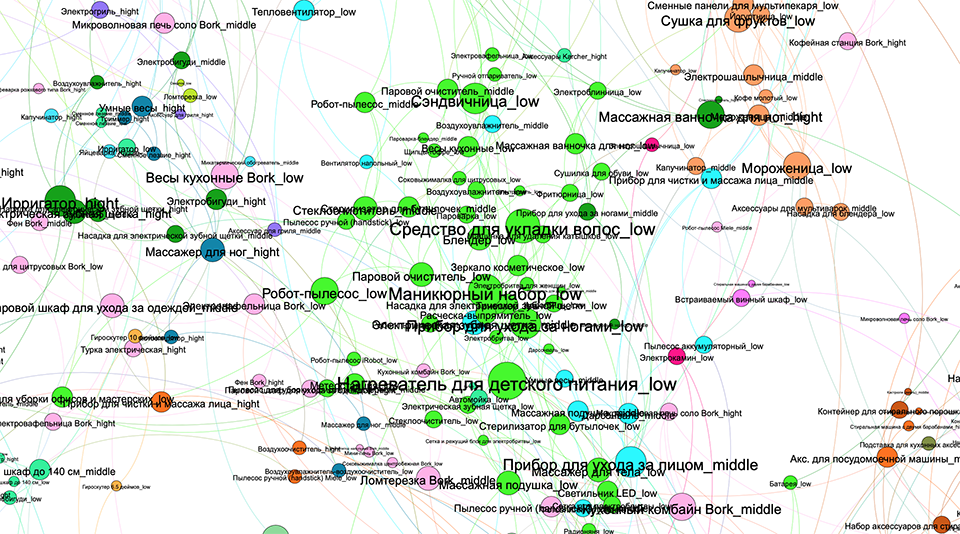
Эти результаты можно использовать сами по себе для разведывательного анализа, а можно двинуться дальше и относить каждого пользователя к одному из выделенных сообществ.
Графовый подход довольно сильно отличается от обычных методов машинного обучения. Работать с ним одновременно и сложно и легко. Сложно потому, что структура графов запутанней, чем структура обычной таблицы, и работа с ней требует знания специальных методов. Легко поскольку графы часто наглядны, хорошо поддаются визуализации, а те самые специфичные методы часто можно объяснить на пальцах.
Литература
- Dacrema, M. F., Cremonesi, P., & Jannach, D. (2019). Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches. Proceedings of the 13th ACM Conference on Recommender Systems, 101–109. https://doi.org/10.1145/3298689.3347058
- Rykov Yuri, Nagornyy Oleg, Koltsova Olessia, Natta Herbert, Kremenets Alexander, Manovich Lev, Cerrone Damiano, & Crockett Damon. (2016). Semantic and Geospatial Mapping of Instagram Images in Saint-Petersburg. Proceedings of the Artificial Intelligence and Natural Language, 110–113. http://fruct.org/publications/abstract-AINL-FRUCT-2016/files/Ryk.pdf
- Semage, L. (2017). Recommender Systems with Random Walks: A Survey. ArXiv:1711.04101 [Cs]. http://arxiv.org/abs/1711.04101
- Андрей Кузнецов. (2020, May 18). Графовые рекомендации групп в Одноклассниках. Habr. https://habr.com/ru/company/odnoklassniki/blog/499192/
- Leeuwenberg, A., Vela, M., Dehdari, J., & Genabith, J. van. (2016). A Minimally Supervised Approach for Synonym Extraction with Word Embeddings. The Prague Bulletin of Mathematical Linguistics, 105(1), 111–142. https://doi.org/10.1515/pralin-2016-0006
- Goyal, P., & Ferrara, E. (2018). Graph Embedding Techniques, Applications, and Performance: A Survey. Knowl. Based Syst. https://doi.org/10.1016/j.knosys.2018.03.022
Комментарии