Сбор данных с сети при помощи Python
Устройство веба
Клиент-серверная архитектура
Компьютеры, подключенные к сети называются клиентами и серверами. Схема обмена информацией выглядит приблизительно так:

Клиенты являются обычными пользователями, подключенными к Интернету посредством устройств и программного обеспечения, доступного на этих устройствах (как правило, браузер, например, Firefox или Chrome).
Серверы - компьютеры, которые хранят веб-страницы, сайты или приложения. Когда клиентское устройство пытается получить доступ к веб-странице, копия страницы загружается с сервера на клиентский компьютер для отображения в браузере пользователя.
HTTP как основной протокол передачи данных
Связь между клиентом и сервером осуществляется по определённому протоколу, обычно это HTTP (HyperText Transfer Protocol). Каждое HTTP-сообщение состоит из трёх частей, которые передаются в указанном порядке:
- Стартовая строка (Starting line) — определяет тип сообщения;
- Заголовки (Headers) — характеризуют тело сообщения, параметры передачи и прочие сведения;
- Тело сообщения (Message Body) — непосредственно данные сообщения. Обязательно должно отделяться от заголовков пустой строкой.
Тело сообщения может отсутствовать, но стартовая строка и заголовок являются обязательными элементами.
Стартовая строка
Стартовые строки различаются для запроса и ответа.
Строка запроса выглядит так: Метод URI HTTP/Версия.
Самые часто используемые методы это GET и POST (ещё существую DELETE, PUT, HEAD и другие).
GET используется для запроса содержимого указанного ресурса, POST применяется для передачи пользовательских данных заданному ресурсу.
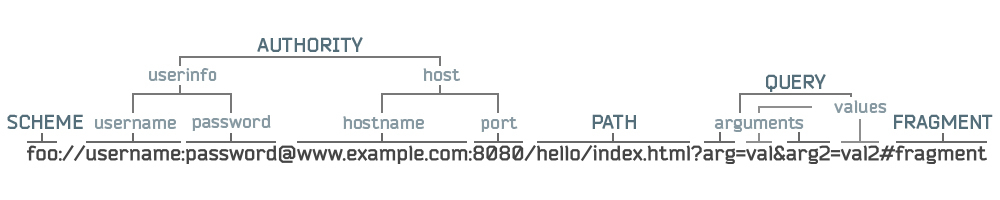
Структура URI: <схема>:[//[<логин>:<пароль>@]<хост>[:<порт>]][/<URL‐путь>][?<параметры>][#<якорь>].
Cтрока ответа сервера имеет следующий формат: HTTP/Версия КодСостояния Пояснение.
Код состояния является частью первой строки ответа сервера. Он представляет собой целое число из трёх цифр. Первая цифра указывает на класс состояния. За кодом ответа обычно следует отделённая пробелом поясняющая фраза на английском языке, которая разъясняет человеку причину именно такого ответа. Список кодов состояния на wiki.
Заголовки
Заголовки HTTP (англ. HTTP Headers) — это строки в HTTP-сообщении, содержащие разделённую двоеточием пару имя-значение.
Тело сообщение
Непосредственно сообщение в формате HTML, JSON и др.
Загрузка данных при помощи модуля request
Библиотека requests — это обёртка над другой, более низкоуровневой библиотекой urllib3, упрощающая доступ ко многим функциям.
В requests имеется:
- Множество методов http аутентификации
- Сессии с куками
- Полноценная поддержка SSL
- Различные методы .json(), которые вернут данные в нужном формате
- Проксирование
- Грамотная и логичная работа с исключениями
Загрузка данных с обычной интернет-страницы
Вот как выглядит HTTP-запрос методом GET с помощью requests:
import requests r = requests.get("https://www.hse.ru/") print(f"Код состояния: {r.status_code}.") print(f"Заголовки: {r.headers['content-type']}.")
Заголовки: text/html; charset=utf-8.
Получить HTML можно с помощью свойства text:
r.text[:500]
Загрузка динамически подгружаемого контента
В качестве примера рассмотрим сайт meduza.io. Зайдите на него и посмотрите через Chrome DevTools, как в нём динамечески подгружается контент. Определим url, на который делаются запросы.
Загрузка информации с защищённых сайтов
Загрузим информацию с сайта мониторинга трудоустройства выпускников: http://vo.graduate.edu.ru/
par_dict = {"id":45,"page":1,"params":{}}
headers = { "Accept": "application/json, text/javascript, */*; q=0.01", "Accept-Encoding": "gzip, deflate", "Accept-Language": "en-US,en;q=0.9,ru-RU;q=0.8,ru;q=0.7,la;q=0.6", "Connection": "keep-alive", "Content-Length": "100", "Content-Type": "application/json; charset=UTF-8", "Cookie": "_ym_uid=15260890961045257376; _ym_isad=1; _ym_visorc_31062401=w; _vagrant_session=V2Qwb3V0aWc4K3NDVW1KVkdxQ0xzZjEyL3JIM2JuSlBGeFJyTEJhUHVXZkZEWnArdUJ6eEVXRFJBcmhrQVh0dWtpVG9iQ0g0UDJXNmtIR0lYUkhJaDhEMkVscUdvSzZhOUFJSlVDSUlqTTlzdXJEY0dpY1Jsa1Q5SzRSb01VdDRDWGVuaGtzSStaazYyYmdnOWFxcWRvSkJ2RFhxM0hadHdyT3hUNEgrY0hFPS0tUTNrUmY2eUx0bXVQdDlYbTkxZzFhQT09--346f51dc5bbd378a982946b4dc5b95d5b5e3038a", "Host": "vo.graduate.edu.ru", "Origin": "http://vo.graduate.edu.ru", "Referer": "http://vo.graduate.edu.ru/registry", "Save-Data": "on", "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36", "X-CSRF-Token": "ZxpQgT3/JsEF/evo5FFLH2niFgeDSrdl8BLQ798xzHiG3umyqLy/Yt61aMwx9jd92/2hitrsaSGN5siwVLrGRQ==", "X-Requested-With": "XMLHttpRequest" }
par_json = json.dumps(par_dict)
r = requests.post("http://vo.graduate.edu.ru/graphs/getGraph", data=par_json)
r
r = requests.post("http://vo.graduate.edu.ru/graphs/getGraph", data=par_json, headers=headers) r
HTML и его парсинг с помощью BeautifulSoup
HTML — теговый язык разметки документов. Любой документ на языке HTML представляет собой набор элементов, причём начало и конец каждого элемента обозначается специальными пометками — тегами. Элементы могут быть пустыми, то есть не содержащими никакого текста и других данных (например, тег перевода строки <br>). В этом случае обычно не указывается закрывающий тег. Кроме того, элементы могут иметь атрибуты, определяющие какие-либо их свойства (например, размер шрифта для тега <font>). Атрибуты указываются в открывающем теге. Вот примеры фрагментов HTML-документа:
<a href="http://www.example.com">Здесь элемент содержит атрибут href, то есть гиперссылку.</a>
А вот пример пустого элемента: <br> и какой-то текст
даст следующее:
Текст между двумя тегами — открывающим и закрывающим. Здесь элемент содержит атрибут href, то есть гиперссылку. А вот пример пустого элемента:
и какой-то текст
Регистр, в котором набрано имя элемента и имена атрибутов, в HTML значения не имеет (в отличие от XHTML). Элементы могут быть вложенными.
Для парсинга HTML существуют разные библиотеки, но чаще всего используется BeautifulSoup. Для тех, кто занком с jQuery более удобным вариантом может быть библиотека pyquery.
from bs4 import BeautifulSoup
BS поддерживает разные парсеры html: https://www.crummy.com/software/BeautifulSoup/bs4/doc/#installing-a-parser
soup = BeautifulSoup("какой-то текст <b class='class_name', id='id_attr'>Полужирный текст</b> <i>И ещё немножко</i>", "lxml") soup
какой-то текст Полужирный текст И ещё немножко
btag = soup.b btag
dir(btag)
'XML_FORMATTERS',
'__bool__',
'__call__',
'__class__',
'__contains__',
'__copy__',
'__delattr__',
'__delitem__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattr__',
'__getattribute__',
'__getitem__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__unicode__',
'__weakref__',
'_all_strings',
'_attr_value_as_string',
'_attribute_checker',
'_find_all',
'_find_one',
'_formatter_for_name',
'_is_xml',
'_lastRecursiveChild',
'_last_descendant',
'_select_debug',
'_selector_combinators',
'_should_pretty_print',
'_tag_name_matches_and',
'append',
'attribselect_re',
'attrs',
'can_be_empty_element',
'childGenerator',
'children',
'clear',
'contents',
'decode',
'decode_contents',
'decompose',
'descendants',
'encode',
'encode_contents',
'extract',
'fetchNextSiblings',
'fetchParents',
'fetchPrevious',
'fetchPreviousSiblings',
'find',
'findAll',
'findAllNext',
'findAllPrevious',
'findChild',
'findChildren',
'findNext',
'findNextSibling',
'findNextSiblings',
'findParent',
'findParents',
'findPrevious',
'findPreviousSibling',
'findPreviousSiblings',
'find_all',
'find_all_next',
'find_all_previous',
'find_next',
'find_next_sibling',
'find_next_siblings',
'find_parent',
'find_parents',
'find_previous',
'find_previous_sibling',
'find_previous_siblings',
'format_string',
'get',
'getText',
'get_attribute_list',
'get_text',
'has_attr',
'has_key',
'hidden',
'index',
'insert',
'insert_after',
'insert_before',
'isSelfClosing',
'is_empty_element',
'known_xml',
'name',
'namespace',
'next',
'nextGenerator',
'nextSibling',
'nextSiblingGenerator',
'next_element',
'next_elements',
'next_sibling',
'next_siblings',
'parent',
'parentGenerator',
'parents',
'parserClass',
'parser_class',
'prefix',
'preserve_whitespace_tags',
'prettify',
'previous',
'previousGenerator',
'previousSibling',
'previousSiblingGenerator',
'previous_element',
'previous_elements',
'previous_sibling',
'previous_siblings',
'quoted_colon',
'recursiveChildGenerator',
'renderContents',
'replaceWith',
'replaceWithChildren',
'replace_with',
'replace_with_children',
'select',
'select_one',
'setup',
'string',
'strings',
'stripped_strings',
'tag_name_re',
'text',
'unwrap',
'wrap']
btag.name
btag.name = "span" btag
btag["class"]
btag.attrs
btag["id"] = "some_id" btag
btag.string
btag.string.replace_with("Новый текст") btag
soup.get_text()
sibling_soup = BeautifulSoup("<a><b class='cl'>text1</b><b class='cl'>text2</b></b></a>", "lxml") print(sibling_soup.prettify())
sibling_soup.find("b", attrs={"class": "cl"}) sibling_soup.find("b", class_="cl")
all_b = sibling_soup.find_all("b", class_="cl") all_b
for b in all_b: print(b.get_text())
text2
Загрузка рецептов с eda.ru
import requests from pyquery import PyQuery as pq import json from json import JSONDecodeError from tqdm import tqdm_notebook import pandas as pd
url = "https://eda.ru/recepty?page={}" res = requests.get(url.format(1))
recipes_subcat_list = [] for recipes_cat in pq(res.text).find(".seo-footer .seo-footer__list"): recipes_subcats = pq(recipes_cat).find("li.seo-footer__list-item, li.seo-footer__list-title _empty") for recipes_subcat in recipes_subcats: d = { "title": pq(recipes_subcat).text().split("\xa0\xa0")[0], "href": pq(recipes_subcat).find("a").attr("href"), "num": int(pq(recipes_subcat).text().split("\xa0\xa0")[1]) } recipes_subcat_list.append(d)
data = {} for rec_cat in recipes_subcat_list: print(rec_cat["title"]) has_items = True page = 1 while has_items: res = requests.get("https://eda.ru/{cat}?page={page}".format(cat=rec_cat["href"], page=page)).text if len(pq(res).find(".recipes-page__recipes .tile-list__horizontal-tile")): page += 1 for recipe in pq(res).find(".recipes-page__recipes .tile-list__horizontal-tile"): title = pq(recipe).find(".horizontal-tile__item-title").text() href = pq(recipe).find(".horizontal-tile__item-title a").attr("href") # print("Page {}, URL {}".format(page, href), end="\r") img_src = pq(recipe).find(".horizontal-tile__preview .lazy-load-container").attr("data-src") booked = int(pq(recipe).find(".js-bookmark__counter").text()) likes = int(pq(recipe).find(".widget-list__like-count").text().split()[0]) dislikes = int(pq(recipe).find(".widget-list__like-count").text().split()[1]) time_to_cook = pq(recipe).find(".prep-time").text() portions = pq(recipe).find(".js-portions-count-print").text() ingredients = [] for ingredient in pq(recipe).find(".ingredients-list .ingredients-list__content-item"): try: attr = pq(ingredient).attr("data-ingredient-object") ingredients.append(json.loads(attr.replace('""', '"'))) except JSONDecodeError as err: print(pq(ingredient).attr("data-ingredient-object")) break data[href] = { "title": title, "img_src": img_src, "ingredients": ingredients, "booked": booked, "likes": likes, "dislikes": dislikes, "time_to_cook": time_to_cook, "portions": portions, "category": rec_cat["title"] } else: has_items = False
len(data)
for num, d in enumerate(data): data[d]["id"] = num
json.dump(data, open("recipes.json", "wt", encoding="utf8"))
data = json.load(open("recipes.json", "rt", encoding="utf8"))
df = pd.DataFrame.from_dict(data, orient="index")
df["img_src"].isnull().sum()
df["category"].head()
/recepty/bulony/bulon-kurinij-s-kleckami-iz-maci-16656 Куриный бульон
/recepty/bulony/bulon-ovoschnoj-14259 Овощной бульон
/recepty/bulony/holodec-iz-teljatini-kurinih-potroshkov-23603 Холодец
/recepty/bulony/klassicheskiy-svetlyy-kurinyy-bulon-93912 Куриный бульон
Name: category, dtype: object
df.to_msgpack("recipes.msg")
for url, d in tqdm_notebook(data.items()): if d["img_src"]: if d["id"] in range(14419, 40000): # для возобновления закачки с какого-либо момента url = "https:" + d["img_src"] res = requests.get(url) path = "imgs/" + str(d["id"]) + "." + d["img_src"].split(".")[-1] open(path, 'wb').write(res.content)
cat = {} for recipes_list in pq(res.text).find(".seo-footer .seo-footer__list"): rec_lis = pq(recipes_list).find("li") cat_name = pq(rec_lis[0]).text().split("\xa0\xa0")[0] for rec_li in pq(rec_lis[1:]): subcat_name = pq(rec_li).text().split("\xa0\xa0")[0] cat[subcat_name] = cat_name
for num, d in enumerate(data): data[d]["sup_category"] = cat[data[d]["category"]]
Загрузка данных с vk.com
- Создать standalone приложение.
- Скопировать Service token.
- Выбрать метод API, который будет вызываться.
- Сформировать запрос как написано в документации.
- Сделать запрос.
import requests access_token = '0b9765dd0b9765dd0b9765dd640bfff4a600b970b9765dd57ca9d0a3a19de66999e2ac0' api_version = '5.89' res = requests.get(f'https://api.vk.com/method/users.get?user_ids=1,23,4,3&access_token={access_token}&v={api_version}') res.json()
'first_name': 'Pavel',
'last_name': 'Durov',
'is_closed': False,
'can_access_closed': True},
{'id': 23,
'first_name': 'Andrey',
'last_name': 'Stolbovsky',
'is_closed': False,
'can_access_closed': True},
{'id': 4,
'first_name': 'DELETED',
'last_name': '',
'deactivated': 'deleted'},
{'id': 3,
'first_name': 'DELETED',
'last_name': '',
'deactivated': 'deleted'}]}
res = requests.get(f'https://api.vk.com/method/wall.get?domain=memesocfuck&count=1&access_token={access_token}&v={api_version}') res.json()
'items': [{'id': 605,
'from_id': -135403715,
'owner_id': -135403715,
'date': 1541948582,
'marked_as_ads': 0,
'post_type': 'post',
'text': 'От создателей\nБуси и Жужи\nСоциальных Асоциологов \nСедовского репа\nи скамейки СЕ-ДОВА \n\nПредставляем вам SKIBIDI ПО-СЕДОВСКИ\n\nhttps://youtu.be/YEK2sKI8YwU\n\nС любовью,\nДля Седова ❤️',
'is_pinned': 1,
'attachments': [{'type': 'link',
'link': {'url': 'https://youtu.be/YEK2sKI8YwU',
'title': 'SKIBIDI по-седовски!!',
'caption': 'youtu.be',
'description': '',
'photo': {'id': 456245719,
'album_id': -2,
'owner_id': 100,
'sizes': [{'type': 'k',
'url': 'https://pp.userapi.com/c845420/v845420877/129e63/0vnhqlFlxC8.jpg',
'width': 1074,
'height': 480},
{'type': 'l',
'url': 'https://pp.userapi.com/c845420/v845420877/129e62/Opmg1v6_rBE.jpg',
'width': 537,
'height': 240},
{'type': 'm',
'url': 'https://pp.userapi.com/c845420/v845420877/129e5f/PdcadzCcVpc.jpg',
'width': 130,
'height': 73},
{'type': 'p',
'url': 'https://pp.userapi.com/c845420/v845420877/129e61/Lqsg34A6fOk.jpg',
'width': 260,
'height': 146},
{'type': 's',
'url': 'https://pp.userapi.com/c845420/v845420877/129e5e/MA14Y-Xq9vk.jpg',
'width': 75,
'height': 42},
{'type': 'x',
'url': 'https://pp.userapi.com/c845420/v845420877/129e60/Mfbiq8T2PBU.jpg',
'width': 150,
'height': 84}],
'text': '',
'date': 1541948587}}}],
'post_source': {'type': 'api', 'platform': 'iphone'},
'comments': {'count': 4, 'can_post': 1, 'groups_can_post': True},
'likes': {'count': 115, 'user_likes': 0, 'can_like': 1, 'can_publish': 1},
'reposts': {'count': 5, 'user_reposted': 0},
'views': {'count': 2983}}]}}
Сложности
Не всегда получить текст страницы бывает так просто, поскольку в современные веб-приложения загружают контент динамически, а URL при этом не изменяется (хотя должен бы). Для примера посмотрите на сайты https://www.1tv.ru/news и https://gorod55.ru/news. В таком случае при помощи Инструментов разработчика придётся отслеживать, какие запросы делает страница, и искать среди них те, которые возвращают нужную информацю.
Самостоятельная работа
Скачайте 100 последних статей с раздела "Истории" сайта meduza.io. Текст и название каждой статьи сохраните в отдельном текстовом файле. В отдельном JSON-файле сохраните мета-информацию о статьях — время публикации и url — так, чтобы можно было восстановиться связь между текстом и мета-информацией.
Комментарии