Построение ансамблей моделей
Ансамбль методов в статистике и обучении машин использует несколько обучающих алгоритмов с целью получения лучшей эффективности прогнозирования, чем могли бы получить от каждого обучающего алгоритма по отдельности.
- Ансамбли более гибкие, они обладают большим числом параметров, чем отдельные модели.
- В теории, из-за этого они склонные переобучаться, но на практике наоборот.
- Вычисление предсказания ансамбля обычно требует больше вычислений, чем предсказание одной модели.
- Ансамбли склонны давать результаты лучше, если имеется существенное отличие моделей. Если модели очень похожи, то качество итоговой модели может быть даже хуже, т.к. ошибки усиливаются.
Простое усреднение
from sklearn.ensemble import VotingClassifier ensemble=VotingClassifier(estimators=[('Decision Tree', decisiontree), ('Random Forest', forest)], voting='soft', weights=[2,1]).fit(train_X,train_Y) print('The accuracy for DecisionTree and Random Forest is:',ensemble.score(test_X,test_Y))
Блендинг или усреднение (можно взвешенное)
Устредняем результаты нескольких моделей.
Бэггинг
Бэггинг – технология классификации, где в отличие от бустинга все элементарные классификаторы обучаются и работают параллельно (независимо друг от друга). Идея заключается в том, что классификаторы не исправляют ошибки друг друга, а компенсируют их при голосовании. Базовые классификаторы должны быть независимыми, это могут быть классификаторы основанные на разных группах методов или же обученные на независимых наборах данных. Во втором случае можно использовать один и тот же метод. Бэггинг позволяет снизить процент ошибки классификации в случае, когда высока дисперсия ошибки базового метода.
Метод бэггинга (bagging, bootstrap aggregation) был предложен Л. Брейманом в 1996 году.
 Пример с сайта XGBoost
Пример с сайта XGBoost
Преимущества
- Помогает против переобучения.
- Улучшает качество.
- Хорошо распараллеливается.
Недостатки
- Требует больше времени.
- Не используется весь набор данных.
Параметры бэггинга
- Параметры выборки по строкам (или бустраппинг).
- Параметры выборки по столбцам.
- Количество моделей.
- Перемешивание.
- Параметры моделей.
Назовите очень известный алгоритм машинного обучения, построенный по принципе бэггинга.
Бустинг
Бустинг (англ. boosting — улучшение) — это процедура последовательного построения композиции алгоритмов машинного обучения, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов.
Все началось с вопроса о том, можно ли из большого количества относительно слабых и простых моделей получить одну сильную. Оказалось, можно.
В течение последних 10 лет бустинг остаётся одним из наиболее популярных методов машинного обучения, наряду с нейронными сетями и машинами опорных векторов. Главную роль в популяризации бустинга сыграли ML соревнования, в особенности kaggle. Основные причины — простота, универсальность, гибкость (возможность построения различных модификаций), и, главное, высокая обобщающая способность.
Бустинг над решающими деревьями считается одним из наиболее эффективных методов с точки зрения качества классификации.
Основные виды бустинга:
- Основанные на весах
- Основанные на остатках
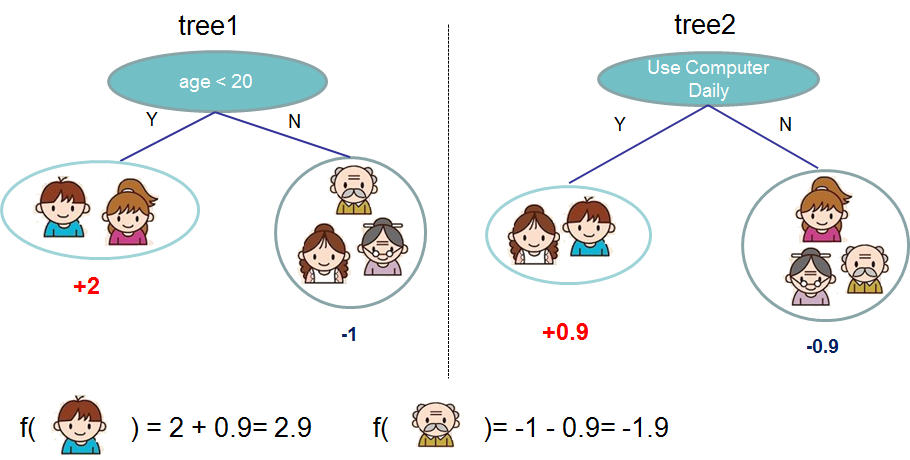
Примерно так работает AdaBoost — первый популярный алгоритм бустинга. Подробнее о нем здесь
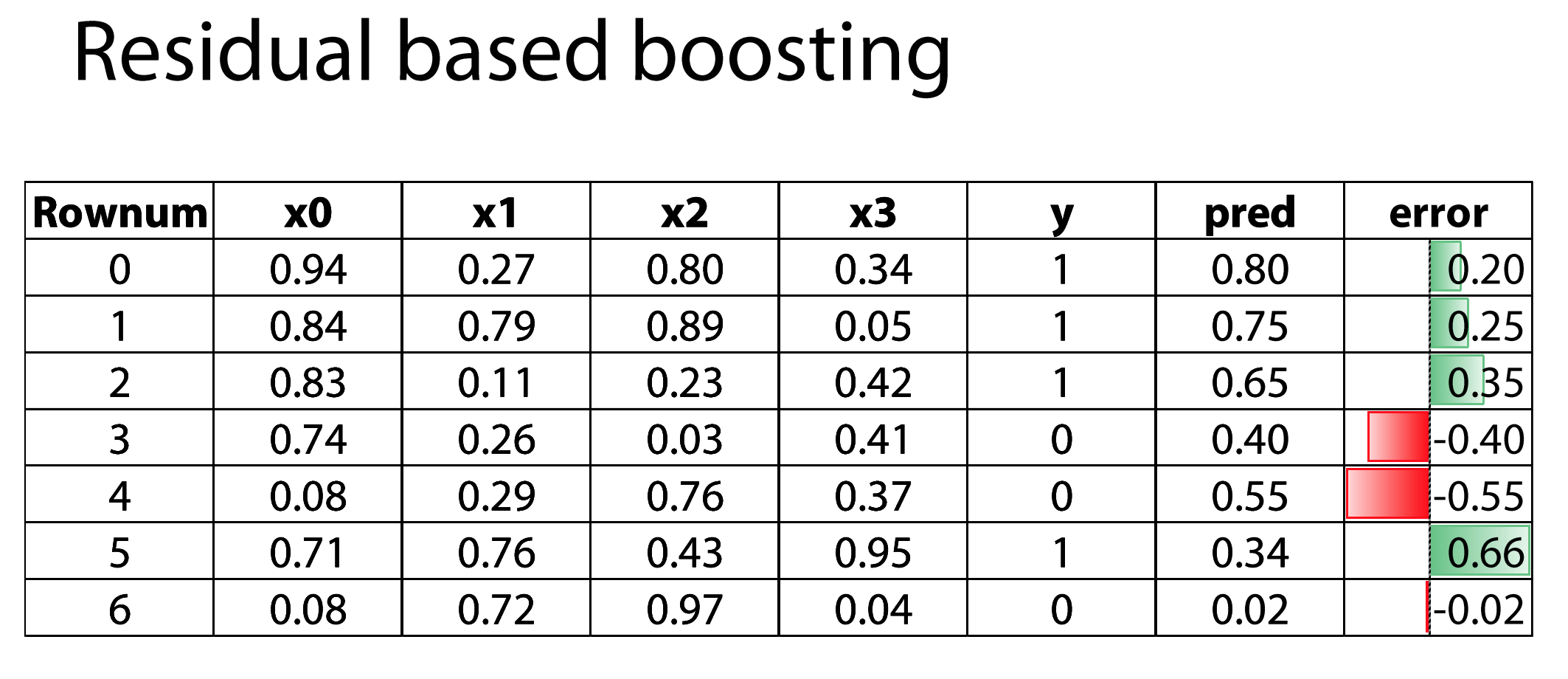
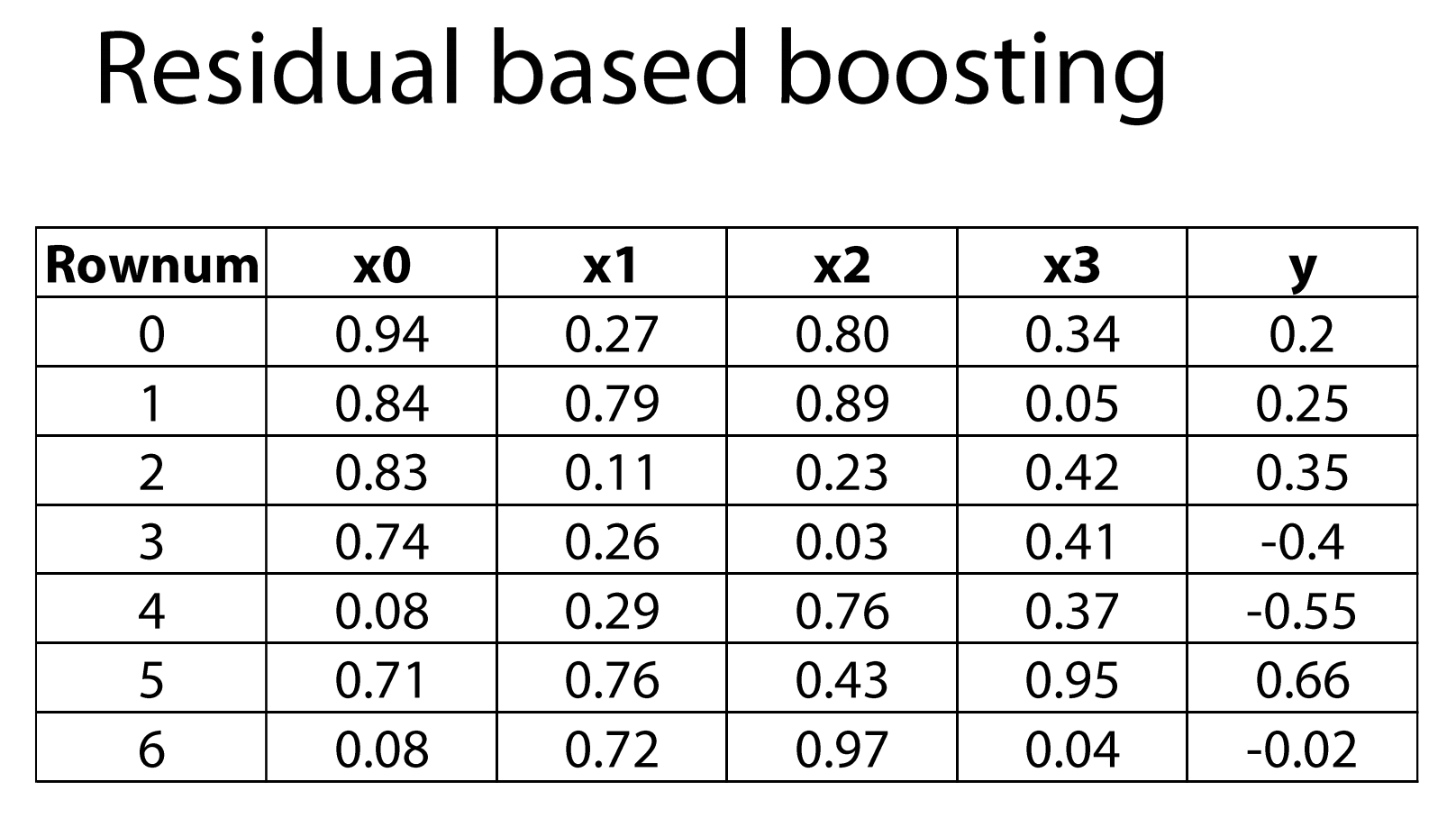
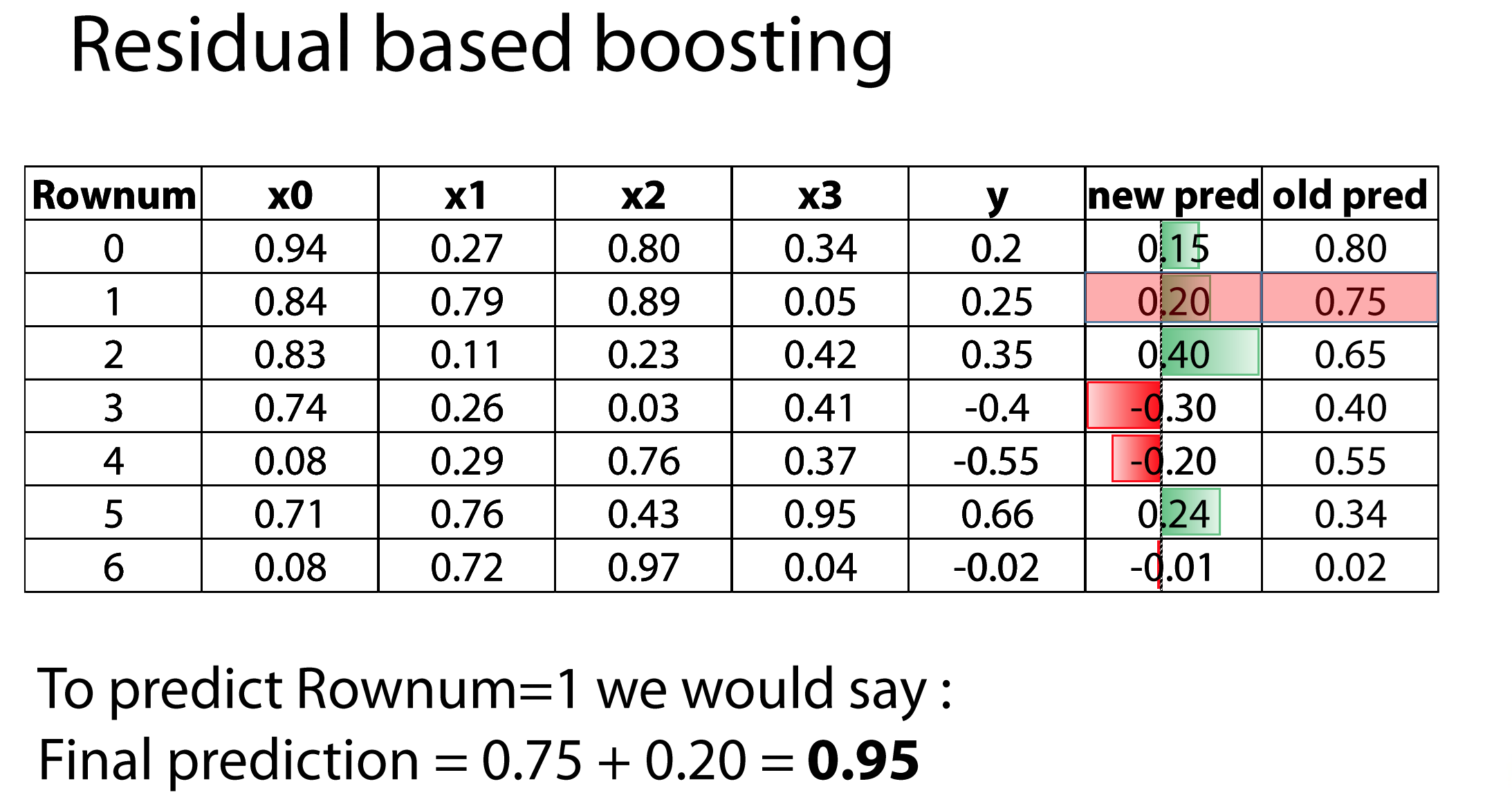
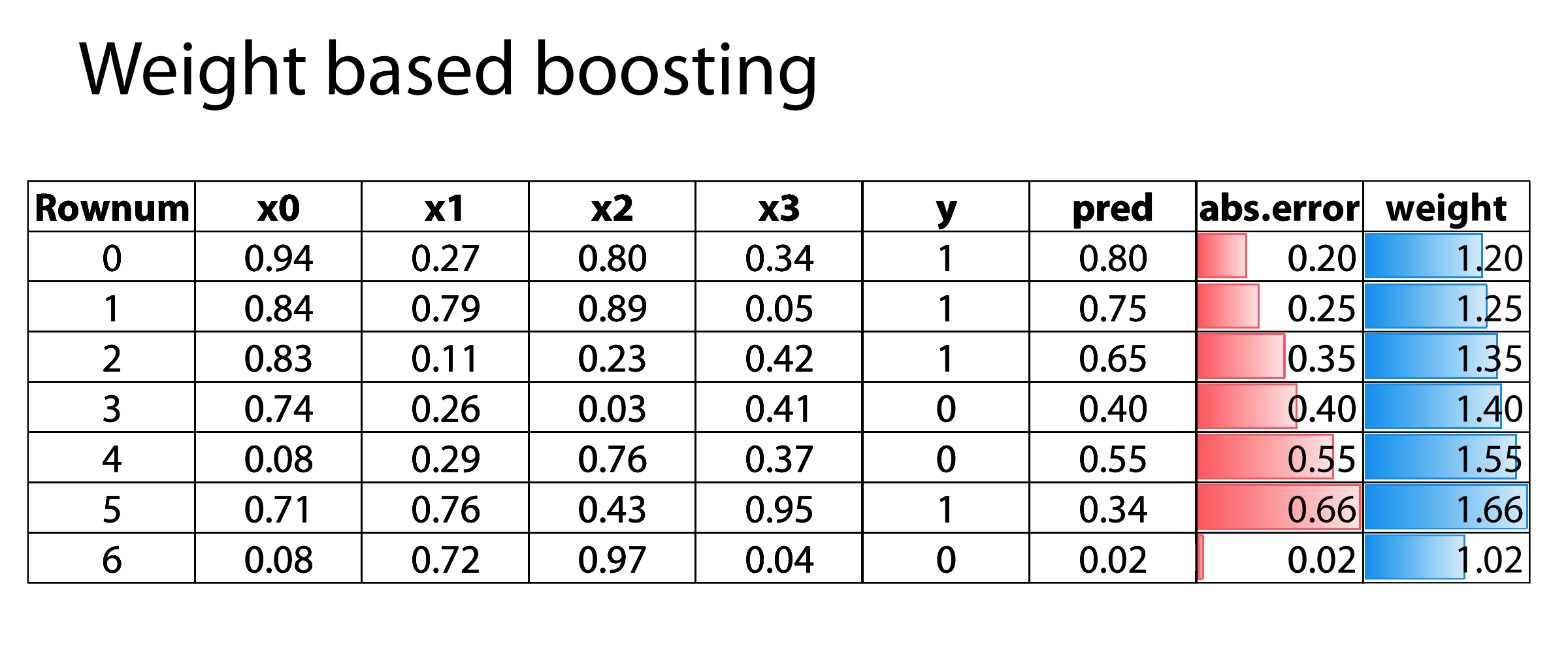
Параметры бустинга
- learning rate — как сильно мы доверяем модели? Умножаем LR на вес.
- Количество моделей. Чем больше моделей, тем ниже LR.
- Тип входных моделей — любая, которая принимает веса.
Эта схема используется в самых популярных и эффективных библиотеках машинного обучения XGBoost, LightGBM, CatBoost.
Как работает XGBoost хорошо объясняется на сайте библиотеки, поэтому лучше поговорим об отличительных особенностях CatBoost. Названием библиотеки авторы акцентируют наше внимание на хороших результатах, которые библиотека показывает на категориальных данных. Это достигается несколькими способами:
- автоматическое проеобразование категориальных признаков.
- mean encoding с валидацией
Помимо этого в CatBoost есть ещё много приятных вещей, таких как втроенная кросс-валидация, сохранение моделей, визуализация процесса обучения, неплохая скорость работы с поддержкой GPU.
Стекинг (Stacked Generalization или Stacking)
Стекинг был предложен Д. Волпертом в 1992 году.
Основная идея стекинга заключается в использовании базовых классификаторов для получения предсказаний (метапризнаков) и использовании их как признаков для некоторого ”обобщающего” алгоритма (метаалгоритма). Иными словами, основной идеей стекинга является преобразование исходного пространства признаков задачи в новое пространство, точками которого являются предсказания базовых алгоритмов. Предлагается сначала выбрать набор пар произвольных подмножеств из обучающей выборки, затем для каждой пары обучить базовые алгоритмы на первом подмножестве и предсказать ими целевую переменную для второго подмножества. Предсказанные значения и становятся объектами нового пространства.
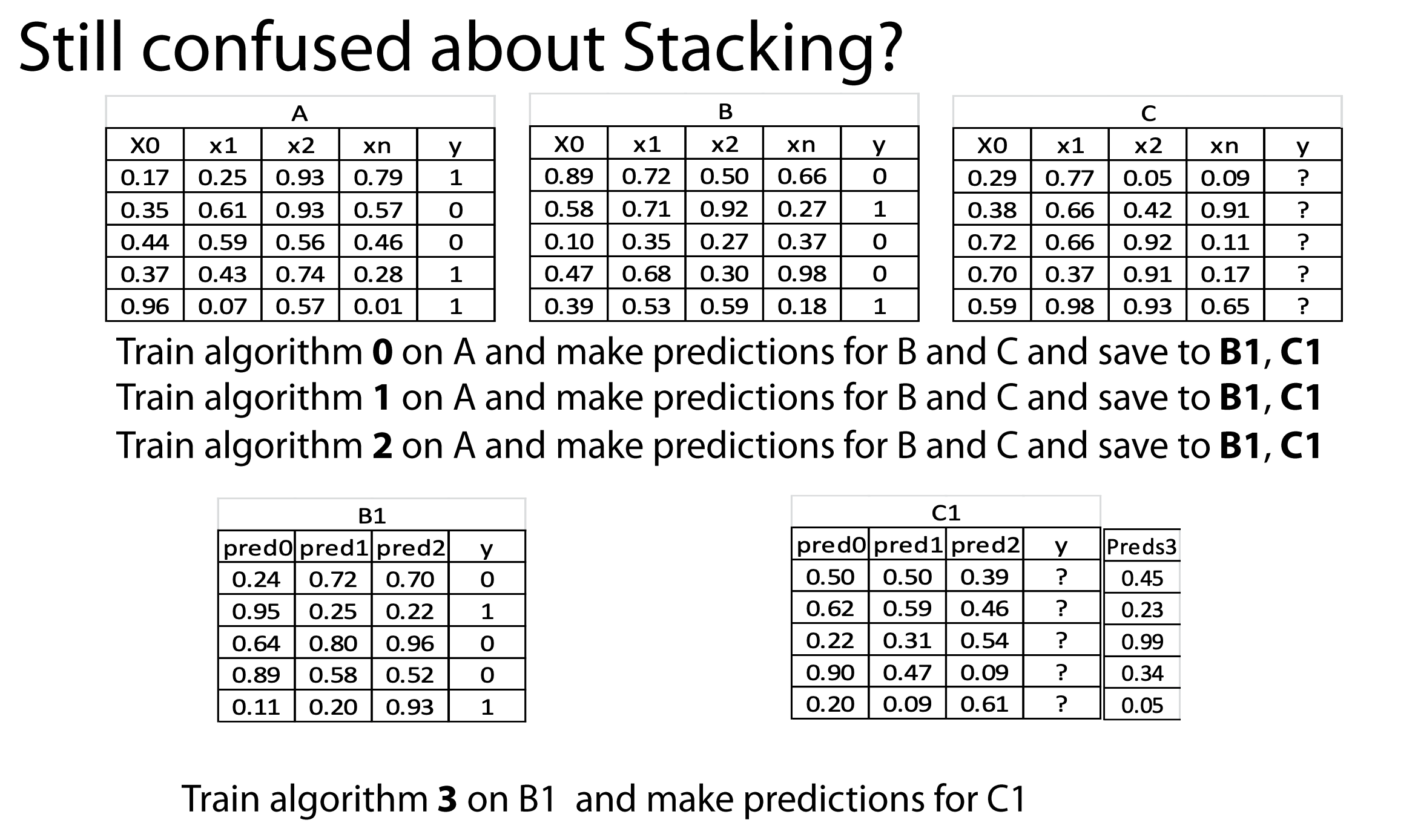
Особенности стекинга
- Поскольку в стекинге мета-модель обучается на ответах уже натренированных алгоритмов, то они сильно коррелируют. Для борьбы с этим часто базовые алгоритмы не сильно оптимизируют. Иногда здорово срабатывают идеи настройки не на целевой признак, а, например, на разницу между каким-то признаком и целевым.
- В отличие от бустинга и традиционного бэгинга при стекинге можно (и нужно!) использовать алгоритмы разной природы (например, гребневую регрессию вместе со случайным лесом). Для формирования мета-признаков используют, как правило, регрессоры.
- Недостаточно просто взять и состекать различные алгоритмы, нужно подстраиваться под особенности работы каждого из них. Например, если есть категориальные признаки с малым (3-4) числом категорий, то алгоритму «случайный лес» их можно подавать «как есть», а вот для регрессионных моделей нужно предварительно выполнить one-hot-кодировку.
- Очень полезный приём, о котором часто забывают — преобразование (деформация) метапризнакового пространства. Скажем, вместо стандартных метапризнаков (ответов алгоритмов) можно использовать мономы над ними (например, все попарные произведения).
- Стекинг можно делать многоуровневым. Готовое решение — StackNet, который является дипломной работой одного из чемпионов соревнований kaggle — kaz-Anova.
Simple holdout scheme
- Разделите тренировочные данные на три части:
partAиpartBиpartC. - Постройте N разнородных моделей на
partA, прогнозируйте дляpartB,partC,test_data, получите мета-признакиpartB_meta,partC_metaиtest_metaсоответственно. - Обучите метамодель на
partB_meta, проверяя её гиперпараметры наpartC_meta. - Когда метамодель будет валидирована, обучите ее на [
partB_meta,partC_meta] и прогнозируйте дляtest_meta.
Meta holdout scheme with OOF meta-features
- Разбейте тренировочную выборку
train dataна несколько частей (фолдов), затем последовательно перебирая фолды обучите N базовых алгоритмов на всех фолдах, кроме одного, а на оставшемся получите ответы базовых алгоритмов и трактуйте их как значения соответствующих признаков на этом фолде. После этого шага для каждого объекта вtrain_dataу нас будет N мета-признаков (out-of-fold predictions, OOF). Назовем ихtrain_meta. - Обучите модели на
train dataи предскажитеtest data. Назовём эти признакиtest_meta. - Разделите
train_metaна две части:train_metaAиtrain_metaB. Обучите мета-модель наtrain_metaA, провалидировав гиперпараметры наtrain_metaB. - Когда мета-модель провалидирована, обучите её на
train_metaи сделайте предсказания наtest_meta.
Cхема валидации честная, если набор, который мы используем для валидации метамоделей, происходит из того же распределения, что и набор мета признаков для теста. Другими словами, в честной схеме валидации набор данных, который мы используем для валидации метамоделей, никоим образом не использовался во время обучения моделей первого уровня.
Рализовывать схему стакинка вручную может быть слегка утомительно (хотя ничего мега-сложно там нет, вот пример реализации на чисто sklearn), поэтому можно воспользоваться библиотекой ML-Ensemble.
# в ML-Ensemble стакинг сводится к этому from mlens.ensemble import SuperLearner ensemble = SuperLearner() ensemble.add(estimators) ensemble.add_meta(meta_estimator) ensemble.fit(X, y).predict(X)
Комментарии