Многоуровневые регрессионные модели
Краткая характеристика многоуровневых регрессионных моделей
Сегодня мы затронем крайне интересную тему смешанных (их ещё называют многоуровневыми или иерархическими) регрессионных моделей. Интересная она по нескольким причинам:
- многоуровневые регрессии — это очень мощный инструмент для проведения конфирматорных исследований и для исследований, измерения в которых производятся в каких-либо группах. С их помощью можно проверить достаточно сложные гипотезы, к которым не удасться подобрать ключик при помощи других методов;
- о них мало кто знает в современном мире курсеророждённых датасаентистов, поскольку, как я уже говорил, смешанные модели модели больше всего подходят для конфирматорынх исследований. Этот тип исследований достаточно редко встречается в индустрии, где основной задачей является предсказание целевой переменной, и усилия, соответственно, направлены на минимизацию ошибки этого предсказания;
- за ними лежит довольно простая, но красивая идея, о которой мы сейчас поговорим.
Смешанная регрессионная модель называется так из-за того, что она содержит как фиксированные, так и случайные эффекты. В остальном же это обычная регрессионная модель.
Другое называние этой группы моделей — многоуровневые регрессионные модели — присходит из-за того, что упомянутые ранее случайные эффекты (или коэффициенты) могут изменяться по группам.
Multilevel models are regressions with coefficients that can vary by groups
Чтобы лучше понять, что из себя представяют такие уровни или группы, представим ситуацию, когда мы исследуем ответы жителей разных стран на одни и те же вопросы. На этом премере видно, что в данных выделяется по меньшей мере два уровня наблюдений — индвидуальный и страновой, причём каждом уровне может быть свой набор переменных.
В процессе исследования мы строим регрессионную модель, в которой моделируем связь между доходом респондента и его удовлетворённостью жизнью. Можно взять и построить регрессионную модель на всех наблюдениях стразу, но, как вы, наверное, знаете, зависимость между счастьем и доходом далеко не одинакова для всех стран — латиноамериканские страны регулярно занимают достаточно высокие места в списке самых счастливых стран, хотя по рейтингу ВВП на душу неселения они занимают аналогичные места, но с конца (для того, чтобы узнать больше об этом кажущемся парадоксе, можете послушать подкаст Freakonomics). По этой причине более правильным решением было бы простроить отдельную регрессионную модель для каждой страны. Если этого не сделать, возникает риск столкнуться с парадоксом Симпсона, о котором мы говорили в предудущей части курса. Напомню, что парадокс Симпосна — это эффект, когда при наличии двух групп данных, в каждой из которых наблюдается одинаково направленная зависимость, при объединении этих групп направление зависимости меняется на противоположное, как на картинке:

Более того, построив одну регрессионную модель, мы нарушим одно из предположений регрессионной модели — независимость наблюдений — а значит не сможем гарантировать корректность полученных оценок. Действительно, если связь между доходом и счастьем различается от страны к стране, то ответы жителей одной страны зависят от какого-то общего фактора — из религиозности, ВВП страны и т.д., а значит их ответы не являются незвисимыми. В случае нарущения одного из предположений ошибки регрессионных коэффициентов становятся недооцененными, а, значит, модель может показать, что коэффициент значим даже если это не так, причём более всего пострадают коэффициенты группового уровня — те самые религиозность и другие.
Однако анализировать множество отдельных моделей крайне неудобно. Частичным решением можно считать добавление фиктивный переменных для каждой страны — обычно именно так и поступают.
Но что, если нам захочется проследить, пример, какие именно характеристики страны влияют связь между доходами и счастьем? Тут на помощь приходят многоуровневые регрессионные модели. В общем виде многоуровневую модель можно представить как регрессию (линейную или обобщенную линейную модель), в которой параметры - коэффициенты регрессии - сами являются вероятностной моделью. Эта модель второго уровня имеет собственные параметры - гиперпараметры модели, которые также оцениваются по данным. Именно эта особенность — моделирование различий между группами — отличает многоуровневые модели от классической регрессии.
В каком-то смысле многоуровневую регрессионную модель действительно можно представить как множество отдельных линейных моделей, построенных для данных второго уровня (страны) на данных первого уровня (респонденты). Причём, в них можно указывать, чем будут различаться модели внутри групп — свободным коэффициентом или коэффициентом наклона.
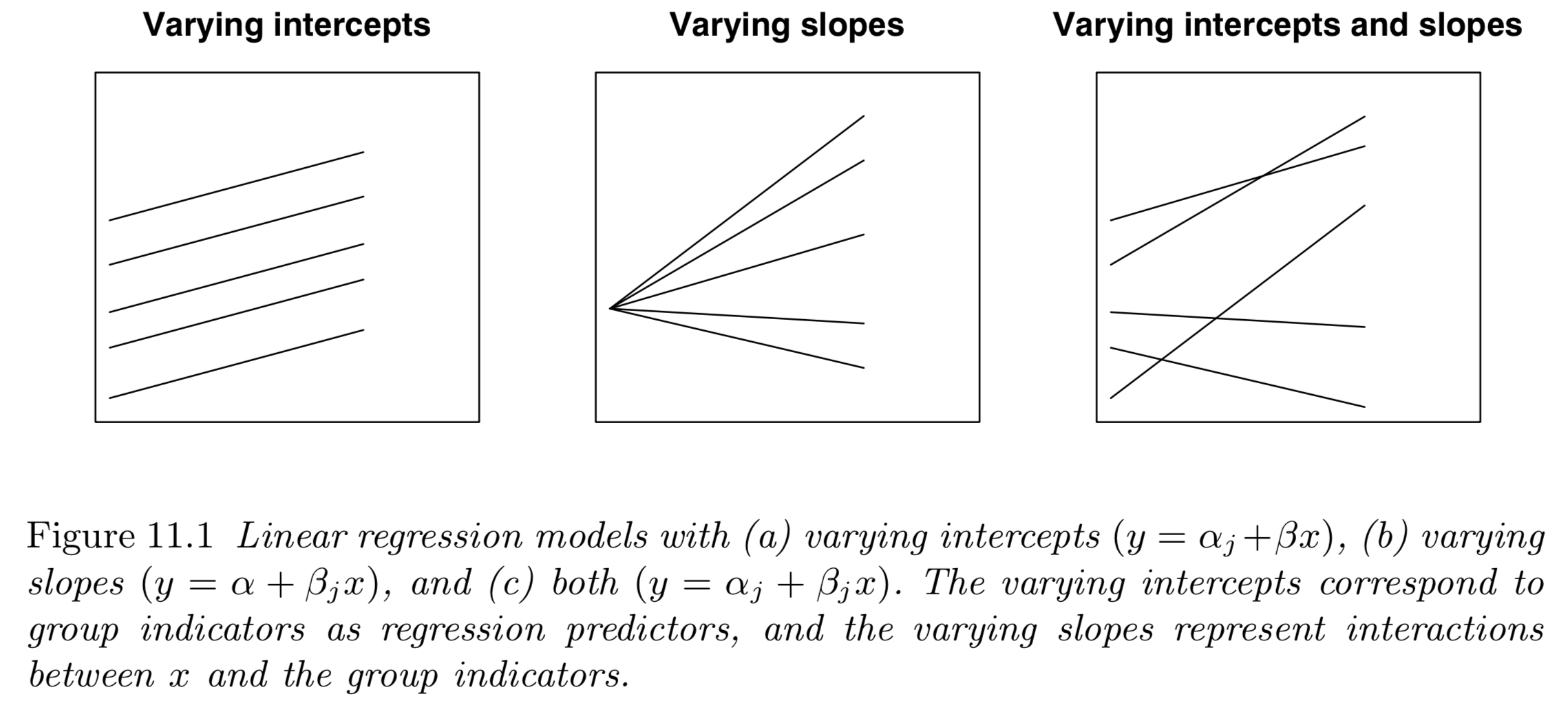
Давайте взглянем на уравнение линейной регрессионной модели и посмотрим, как можно сделать из него многоуровневую. Уравнение обычной регрессионной модели можно записать так:
где в нашем случае — это доход -ого человека, и — коэффициенты модели, — уровень его религиозности, — ошибка предсказания.
Предположим, мы хотим заложить в модель возможность изменения среднего уровня религиозности для каждой страны . Для этого необходимо, чтобы свободный член уравнения, отвечающий за положение прямой относительно оси , принимал разные значения для каждой из стран. переписать свободный член уравнения следующим образом:
где
То есть где и — предикторы на индивидуальном и страновом уровне соответственно, а и — ошибка на этих уровнях.
В более сложном случае мы предполагаем, что не только средний уровнь религиозности может различаться по странам также варьируется характер его зависимости от дохода. Формально это выражается в разном угле наклона регрессионной прямой для каждой из стран, а ещё более формально в следующих уравнениях: где
Многоуровневые модели часто называют моделями со случайными или смешанными эффектами. Термин «случайные эффекты» употребляется в том смысле, что они считаются случайными результатами процесса, прогнозируемого моделью. Напротив, фиксированные эффекты соответствуют либо параметрам, которые не изменяются. Модель смешанных эффектов включает в себя как фиксированные, так и случайные эффекты; например, в модели. По совету Gelman и Hill мы будем избегать этой терминологии.
Говоря о параметрах модели, следует упомнянуть о некоторых ограничениях, связанных с количеством групп второго уровня (в прошлом примере это были страны) — в лучшем случае их должно быть не менее 50 и размер каждой группы не менее 5 наблюдений. Количество групп от 26 до 49 также допустимо, но в этом случае следует валидировать модель с использованием байесовского вывода. Модель с количеством групп на втором уровне менее 26 стоит избегать.
В конце первой вводной части я сошлюсь на выступление Анатолия Карпова о применении смешанных регрессионных моделей при анализе психологических данных.
Чем можно заменить многоуровневые регрессионные модели?
Зачем всё-таки нужны многоуровневые регрессионные модели?
- Позволяют оценивать коэффициенты для каждой из групп, причём даже при малом размере группы (>5 наблюдений).
- Позволяют оценить воздействие переменной группового уровня на переменные индивидуального уровня.
- Лучше моделируют эффекты индивидуального уровня и позволяют удобно предсказывать их значения для разных групп.
- Позволяют контролировать воздействие одной переменной на другую. Одной из основных целей регрессионного анализа является оценка того, как изменяется y, когда изменяется некоторый x, а все остальные входные данные остаются постоянными. Во многих приложениях интерес представляет не общий эффект x, а то, как этот эффект варьируется по группам. В классической статистике мы можем изучить эту вариацию, используя взаимодействия: например, определенная образовательная инновация может быть более эффективной для девочек, чем для мальчиков, или более эффективной для учащихся, которые проявили больший интерес к школе перед поступлением. Многоуровневые модели также позволяют нам изучать эффекты, которые варьируются в зависимости от группы. В классической регрессии оценки различных эффектов могут быть шумными, особенно когда в группе мало наблюдений. Многоуровневое моделирование позволяет нам более точно и надёжно оценивать эти взаимодействия в условиях ограниченных данных. и т.д.
Практика
Давате передохнём от теории и перейдём к практике. Мы будем тренировать навыки построения многоуровневых регрессионных моделей на известном наборе данных об уровне радона в жилых домах. Радон образуется при распаде радия, который находится в грунте, почве и в минеральных составляющих строительных материалов. При плохом воздухообмене в квартире он имеет свойство накапливаться, и при попадании в организм вместе с вдыхаемым воздухом радон распадается на дочерние продукты, которые облучают ткани лёгких. По данным ВОЗ, воздействие этого газа является второй после курения причиной возникновения рака лёгких, этому ВОЗ основала всемирный проект, направленный на уменьшение риска заражения радоном.
Используемый нами набор данных был собран Гельманом и использовался им для иллюстрации работы многоуровневых моделей в работе, на которую я уже ссылался [1] (кстати, подписывайтесь на его блог). На этом наборе данных удобно проверять влияние различных факторов на уровень радона.
Практически все распространённые пакеты для работы с многоуровневыми моделями созданы для R. Мы будем использовать пакет lme4. Вы также можете рассмотреть другие варианты — nlme или plm. При работе в Python можно использовать имплементацию многоуровневых регрессионных моделей из statsmodels, но там имеется довольно ограниченный набор моделей и инструментов для их тестирования и визуализации.
Есть ещё stan, который тоже может моделировать многоуровневые регрессии (и, кстати, имеет интерфейс на Python), но его основная фишка не в этом, да и сам пакет заслуживает отдельной статьи. То же самое применимо к PyMC, и о нём, думаю, мы поговорим позже.
Итак, давайте взглянем на данные. Их составляют измерения радона в различных домохозяйствах. Для удобства анализа все наблюдения были сгруппированы по округам (переменная county). Основной предиктор уровня радона - это этаж, на котором проводилось измерение: подвал или первый этаж. Поскольку радон содержится в грунте, чем ближе к земле проиходит измерение, тем выше должен быть его уровень. Этот предиктор был измерен на уровне домохозяйства, т.е. на первом уровне. На уровне окруда есть дургой важных предиктор - средний уровень радона в данной местности. Задачей исследования, таким образом, будет отследить влияние предикторов на перовом и втором уровне на содержание радона в здании.
radon = read.csv("https://raw.githubusercontent.com/pymc-devs/pymc3/master/pymc3/examples/data/radon.csv") radon$county = as.factor(radon$county) dim(radon)
- 919
- 30
head(radon)
| X | idnum | state | state2 | stfips | zip | region | typebldg | floor | room | ⋯ | pcterr | adjwt | dupflag | zipflag | cntyfips | county | fips | Uppm | county_code | log_radon |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5081 | MN | MN | 27 | 55735 | 5 | 1 | 1 | 3 | ⋯ | 9.7 | 1146.4992 | 1 | 0 | 1 | AITKIN | 27001 | 0.502054 | 0 | 0.83290912 |
| 1 | 5082 | MN | MN | 27 | 55748 | 5 | 1 | 0 | 4 | ⋯ | 14.5 | 471.3662 | 0 | 0 | 1 | AITKIN | 27001 | 0.502054 | 0 | 0.83290912 |
| 2 | 5083 | MN | MN | 27 | 55748 | 5 | 1 | 0 | 4 | ⋯ | 9.6 | 433.3167 | 0 | 0 | 1 | AITKIN | 27001 | 0.502054 | 0 | 1.09861229 |
| 3 | 5084 | MN | MN | 27 | 56469 | 5 | 1 | 0 | 4 | ⋯ | 24.3 | 461.6237 | 0 | 0 | 1 | AITKIN | 27001 | 0.502054 | 0 | 0.09531018 |
| 4 | 5085 | MN | MN | 27 | 55011 | 3 | 1 | 0 | 4 | ⋯ | 13.8 | 433.3167 | 0 | 0 | 3 | ANOKA | 27003 | 0.428565 | 1 | 1.16315081 |
| 5 | 5086 | MN | MN | 27 | 55014 | 3 | 1 | 0 | 4 | ⋯ | 12.8 | 471.3662 | 0 | 0 | 3 | ANOKA | 27003 | 0.428565 | 1 | 0.95551145 |
Модель со случайным свободным коэффициентом (Random intercepts model)
Построим регрессионную модель со свободным коэффициентом, которым может принимать разные значения для разных округов.
Формула этой модели, напомню, выглядит следующим образом:
Для этого вызовем функцию lmer из пакета lme4, в которую запишем формулу модели.
library("lme4") ## Varying intercept & slopes w/ no group level predictors M0 <- lmer(log_radon ~ floor + (1 | county), data=radon)
Синтаксис формулы не сильно отличается от такового для обычных линейных моделей, но есть несколько особенностей, связанных с обозначением многоуровневости (подробности смотрите в документации, стр. 7). В примере выше часть формулы (1 | county) означает, что мы хотим сделать свободный коэффициент случайной переменной, различающейся от округа (county) к округу.
Посмотрим на вывод этой модели. Его можно получить при помощи стандартной функции summary.
summary(M0)
Formula: log_radon ~ floor + (1 | county)
Data: radon
REML criterion at convergence: 2097.5
Scaled residuals:
Min 1Q Median 3Q Max
-4.3597 -0.6253 -0.0016 0.6389 3.4965
Random effects:
Groups Name Variance Std.Dev.
county (Intercept) 0.09948 0.3154
Residual 0.52676 0.7258
Number of obs: 919, groups: county, 85
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.49239 0.04955 30.117
floor -0.66289 0.06765 -9.798
Correlation of Fixed Effects:
(Intr)
floor -0.288
Вывод модели несколько отличается от такового для обычной линейной модели. В нём есть отдельный блок для случайных и фиксированных эффектов. Раздел, посвящённый фиксированным эффектам в целом похож на вывод обычной модели. В нем находятся значения коэффициентов и информация об их значимости. В нашём случае номер этажа, на котором проводилось измерение, находится в обратной связи с уровнем радона. Поднятие на один этаж приводит из уменьшению радона на 0.66 (мне не известны единицы измерения, к тому же зависимая переменная была прологарифмирована, поэтому сложно интерпретировать это значение). Таким образом, уравнение регрессионной прямой для среднего округа записывается как .
В части вывода, посвящённой случайным эффектам, находится стандартные отклонения и дисперсия (просто стандартное отклонение в квадрате) для переменных группового уровня. Стандартное отклонение по стране, равное 0.3154 показывает, как сильно изменяется в уравнении модели, а число 0.7258 показывает вариацию . Сложно как-то интерпретировать это напрямую. То же самое с полем "Correlation of Fixed Effects" — его значение редко пригодится в реальном анализе.
Куда более интересно взглянуть на список случайных эффектов для каждой группы, который можно получить при помощи функций ranef или coef. Первая возвращает только значения случайных эффектов, вторая — и фиксированных тоже.
head(coef(M0)$county) # для первых шести групп из переменной группового уровня county
| (Intercept) | floor | |
|---|---|---|
| AITKIN | 1.2291388 | -0.6628887 |
| ANOKA | 0.9811502 | -0.6628887 |
| BECKER | 1.5066938 | -0.6628887 |
| BELTRAMI | 1.5377713 | -0.6628887 |
| BENTON | 1.4732718 | -0.6628887 |
| BIG STONE | 1.5084495 | -0.6628887 |
Этот вывод означает, что для округа AITKIN регрессионное уравнение выглядит как , для округа ANOKA как и т.д.
Функция ranef показывает, на сколько выше или ниже находится регрессионная прямая в каждом округе. Например, в тех округах, где значение отрицательно — уровень радона ниже, чем в среднем.
head(ranef(M0)$county)
| (Intercept) | |
|---|---|
| AITKIN | -0.26325439 |
| ANOKA | -0.51124297 |
| BECKER | 0.01430059 |
| BELTRAMI | 0.04537812 |
| BENTON | -0.01912135 |
| BIG STONE | 0.01605636 |
Легко заметить, что для получения свободных коэффициентов из первой таблицы нужно просто прибавить к этим значениям значение свободного коэффициента для среднего округа, которое является фиксированной переменной, а значит его можно получить при помощи фукнции fixef.
fixef(M0)
- (Intercept)
- 1.49239317405761
- floor
- -0.662888725670425
(ranef(M0)$county[, 1] + fixef(M0)['(Intercept)'][[1]])[1:5]
- 1.22913878203744
- 0.981150201857783
- 1.50669376251355
- 1.53777129831703
- 1.47327182833173
# вспомогательный код для отрисовки всех графиков в SVG library("Cairo") options(jupyter.plot_mimetypes = 'image/svg+xml') options(warn=-1) # ALERT: отключаем предупреждения из-за кириллицы глобально # предсказываем уровень радона и визуализируем pr0 <- predict(M0, radon) ggplot(data=radon, aes(floor, pr0)) + geom_line(aes(color = county), show.legend = FALSE) + labs(x="Этаж (подвал или 1-й этаж)", y="log(Радон)")
Но как убедиться, значимо ли отличается свободный коэффициент в данной конкретной группе? Проще всего увидеть это различие на графике, который можно получить при помощи функции plot_model из пакета sjPlot, который предоставляет богатые возможности визуализации моделей.
library("sjPlot") set_theme(axis.textsize = .7) plot_model(M0, type = "re")
Линиями на этом графиками обозначины доверительные интервалы для величины случайного эффекта в группах. Если какая-то линия не пересекает вертикальную прямую, соответствующую 0, можно говорить о значимости отличия положения регрессионной прямой для соответствующей группы.
В нашем случае, например, содержание радона в зданиях из города под названием St. Louis (на графике обозначен как STLOUIS, 16-й сверху) значимо меньше, чем в среднем.
Другой способ узнать значимость коэффициентов — использовать пакет lmerTest. Достаточно просто импортировать его и вывод модели, получаемый функцией summary будет расширен.
Однако сам автор пакета lme4 остерегает от того, чтобы полагаться на p-values и доверительные интералы при оценке многоуровневых регрессий, на что у него есть ряд аргументов [2].
Коэффициент детерминации в многоуровневых регрессионных моделях
Вы, возможно, заметили, что в выводе стандартной функции отсутствовала информация о коэффициенте детерминации . Причина тому — сложность определения того, что называть для многоуровневых регрессионных моделей. Только в 2012 году Shinichi Nakagawa и Holger Schielzeth [3] предложили вариант (дополнен Paul C.D. Johnson в 2014 [4]), который стал стандартным способом решения этой проблемы. Их предложение состояло в том, чтобы рассчитывать два варианта — предельный и условный. Предельный показывает долю дисперсии, объяснённую только лишь фиксированными эффектами:
где — дисперсия, объяснённая фиксированными коэффициентами, — количество случайных эффектов, — дисперсия в группе , и — дисперия остатков.
Условный показывает долю дисперсии, объяснённую как фиксированными, так и случайными эффектами:
Давайте рассчитаем предельный и условный самостоятельно [5].
Дисперсия, объяснённая фиксированными коэффициентами, оценивается через дисперсию прогнозов для данных, полученном без учёта случайных переменных.
var_f <- var(predict(M0, re.form=NA))
Дисперсию случайных эффектов можно получить, ипользу функцию VarCorr.
(vars <- as.data.frame(VarCorr(M0)))
| grp | var1 | var2 | vcov | sdcor |
|---|---|---|---|---|
| county | (Intercept) | NA | 0.09948229 | 0.3154081 |
| Residual | NA | NA | 0.52675634 | 0.7257798 |
var_l <- vars1[1,4] var_e <- vars1[2,4]
varf/(varf+var_l+var_e)
(var_f+var_l)/(var_f+var_l+var_e)
Кстати говоря, в пакете sjPlot функция tab_model, которая рисует более опрятную и информативную таблицу, чем обычная summary. В ней уже показываются значения .
tab_model(M0)
| log radon | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 1.49 | 1.40 – 1.59 | <0.001 |
| floor | -0.66 | -0.80 – -0.53 | <0.001 |
| Random Effects | |||
| σ2 | 0.53 | ||
| τ00 county | 0.10 | ||
| ICC county | 0.16 | ||
| Observations | 919 | ||
| Marginal R2 / Conditional R2 | 0.089 / 0.234 | ||
Как видно, они практически совпадают с тем, что мы рассчитали вручную.
Модель со случайным углом наклона (Random Slopes Model)
где
M1 <- lmer(log_radon ~ floor + (floor - 1 | county), data=radon) summary(M1)
Formula: log_radon ~ floor + (floor - 1 | county)
Data: radon
AIC BIC logLik deviance df.resid
2177.0 2196.2 -1084.5 2169.0 915
Scaled residuals:
Min 1Q Median 3Q Max
-3.9444 -0.6790 0.0306 0.6896 3.2931
Random effects:
Groups Name Variance Std.Dev.
county floor 0.0924 0.3040
Residual 0.6081 0.7798
Number of obs: 919, groups: county, 85
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.36241 0.02818 48.355
floor -0.53455 0.08396 -6.367
Correlation of Fixed Effects:
(Intr)
floor -0.336
head(coef(M1)$county)
| (Intercept) | floor | |
|---|---|---|
| AITKIN | 1.36241 | -0.5338824 |
| ANOKA | 1.36241 | -0.8334118 |
| BECKER | 1.36241 | -0.5190840 |
| BELTRAMI | 1.36241 | -0.5458936 |
| BENTON | 1.36241 | -0.4988334 |
| BIG STONE | 1.36241 | -0.5345482 |
predict(M1, radon)[1]
pr1 <- predict(M1, radon) ggplot(data=radon, aes(floor, pr1)) + geom_line(aes(color = county), show.legend = FALSE) + labs(x="Этаж (подвал или 1-й этаж)", y="log(Радон)")
Модель со случайным свободным коэффициентом и углом наклона (Random Intercepts and Slopes Model)
где
M2 <- lmer(log_radon ~ floor + (floor|county), data=radon) tab_model(M2)
Caution! ICC for random-slope-intercept models usually not meaningful. Use `adjusted = TRUE` to use the mean random effect variance to calculate the ICC. See 'Note' in `?icc`.
| log radon | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 1.49 | 1.39 – 1.60 | <0.001 |
| floor | -0.65 | -0.82 – -0.49 | <0.001 |
| Random Effects | |||
| σ2 | 0.51 | ||
| τ00 county | 0.11 | ||
| τ11 county.floor | 0.11 | ||
| ρ01 county | -0.37 | ||
| ICC county | 0.18 | ||
| Observations | 919 | ||
| Marginal R2 / Conditional R2 | 0.086 / 0.257 | ||
pr2 <- predict(M2, radon) set_theme(axis.textsize = 1) ggplot(data=radon, aes(floor, pr2)) + geom_line(aes(color = county), show.legend = FALSE) + labs(x="Этаж (подвал или 1-й этаж)", y="log(Радон)")
set_theme(axis.textsize = .7) plot_model(M2, type = "re")
Сравнение с обычной регрессионной моделью
Сравним выводы многоуровневой регрессионной модели с выводом обычной модели, в которой группирующая переменная присутствует как обычная категориальная переменная с dummy-coding, как это обычно и бывает.
M0_lm <- lm(log_radon ~ floor + county, data=radon) tab_model(M0_lm)
| log radon | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 0.89 | 0.17 – 1.60 | 0.015 |
| floor | -0.69 | -0.83 – -0.55 | <0.001 |
| ANOKA | 0.04 | -0.70 – 0.78 | 0.908 |
| BECKER | 0.66 | -0.43 – 1.75 | 0.234 |
| BELTRAMI | 0.70 | -0.19 – 1.59 | 0.125 |
| BENTON | 0.57 | -0.44 – 1.57 | 0.270 |
| BIG STONE | 0.65 | -0.44 – 1.74 | 0.242 |
| BLUE EARTH | 1.14 | 0.33 – 1.95 | 0.006 |
| BROWN | 1.11 | 0.10 – 2.12 | 0.031 |
| CARLTON | 0.16 | -0.68 – 1.00 | 0.713 |
| CARVER | 0.68 | -0.24 – 1.60 | 0.148 |
| CASS | 0.54 | -0.42 – 1.50 | 0.268 |
| CHIPPEWA | 0.87 | -0.14 – 1.88 | 0.091 |
| … | … | … | … |
| WILKIN | 1.35 | -0.24 – 2.95 | 0.096 |
| WINONA | 0.77 | -0.05 – 1.58 | 0.064 |
| WRIGHT | 0.78 | -0.04 – 1.59 | 0.061 |
| YELLOW MEDICINE | 0.33 | -0.90 – 1.56 | 0.601 |
| Observations | 919 | ||
| R2 / adjusted R2 | 0.287 / 0.214 | ||
Многоуровневая модель с предиктором группового уровня
Концентрация радона в воздухе зависит от геологической обстановки. Например, граниты, в которых много урана, являются активными источниками радона. В геологии измерение содержания радона в воздухе и воде даже применяется для поиска месторождений урана и тория.
В нашем наборе данных имеется подходящий предиктор группового уровня, показывающий количество урана на уровне округа Uppm, где стояли здания, в которых происходило измерение радона. Давайте проверим, действительно ли концентрация урана влияет на уровень радона.
head(radon[, c("county", "Uppm")])
| county | Uppm |
|---|---|
| AITKIN | 0.502054 |
| AITKIN | 0.502054 |
| AITKIN | 0.502054 |
| AITKIN | 0.502054 |
| ANOKA | 0.428565 |
| ANOKA | 0.428565 |
M3 <- lmer(log_radon ~ floor + Uppm + (1|county), data=radon) tab_model(M3)
| log radon | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 0.68 | 0.47 – 0.88 | <0.001 |
| floor | -0.64 | -0.77 – -0.51 | <0.001 |
| Uppm | 0.77 | 0.58 – 0.96 | <0.001 |
| Random Effects | |||
| σ2 | 0.53 | ||
| τ00 county | 0.02 | ||
| ICC county | 0.04 | ||
| Observations | 919 | ||
| Marginal R2 / Conditional R2 | 0.169 / 0.203 | ||
Многоуровневая модель с эффектом взаимодействия между предиктором группового и индивидуального уровня
M4 <- lmer(log_radon ~ floor * Uppm + (floor|county), data=radon) tab_model(M4)
Caution! ICC for random-slope-intercept models usually not meaningful. Use `adjusted = TRUE` to use the mean random effect variance to calculate the ICC. See 'Note' in `?icc`.
| log radon | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | 0.56 | 0.37 – 0.76 | <0.001 |
| floor | -0.13 | -0.61 – 0.36 | 0.606 |
| Uppm | 0.89 | 0.70 – 1.07 | <0.001 |
| floor:Uppm | -0.49 | -0.96 – -0.03 | 0.037 |
| Random Effects | |||
| σ2 | 0.52 | ||
| τ00 county | 0.01 | ||
| τ11 county.floor | 0.08 | ||
| ρ01 county | 0.58 | ||
| ICC county | 0.02 | ||
| Observations | 919 | ||
| Marginal R2 / Conditional R2 | 0.172 / 0.218 | ||
plot_model(M4, type = "int")
Проверка многоуровновости при помощи ICC
Для того, чтобы узнать, следует ли в вашем случае строит многоуровневую модель, или можно обойтись обычно, следует рассчитать коэффициент внутриклассовой корреляции (ICC). ICC вычисляется как отношение межгрупповой дисперсии к общей дисперсии (то есть к сумме межгрупповой и внутригрупповой диспесий), а его формула выглядит следующим образом: ICC можно интерпретировать как долю дисперсии, объясняемой многоуровневостью модели, это доля групповой дисперсии в общей дисперсии. Таким образом, ICC описывает, насколько различаются группы между собой группы. ICC больше 0.1 обычно считается достаточным для построения многоуровневых моделей, хотя чётких критериев тут нет.
Обычно ICC рассчитывается для нулевой модели (её ещё назвают пустой моделью), т.е. модели, в которой заложена только группирующая переменная. Фактически, это обычная модель ANOVA.
empty_model <- lmer (log_radon ~ 1 + (1 | county), data=radon) summary(empty_model)
Formula: log_radon ~ 1 + (1 | county)
Data: radon
REML criterion at convergence: 2184.9
Scaled residuals:
Min 1Q Median 3Q Max
-4.6880 -0.5884 0.0323 0.6444 3.4186
Random effects:
Groups Name Variance Std.Dev.
county (Intercept) 0.08861 0.2977
Residual 0.58686 0.7661
Number of obs: 919, groups: county, 85
Fixed effects:
Estimate Std. Error t value
(Intercept) 1.350 0.047 28.72
0.2977^2 / (0.2977^2 + 0.7661^2)
Рассчитать ICC также можно при помощи функции icc из пакета sjstats, который помимо неё содержит множество разнообразных функций для работы с регрессионными моделями.
library("sjstats") icc(empty_model)
Как видно, эти значения почти плоностью повторяют рассчитанные вручную.
Ограничения многоуровневой регрессионной модели
У многоуровневой регрессионной модели все те же ограничения, что и обычной, плюс несколько специфических.
plot_model(M0, type = "diag")
[[2]]
[[2]]$county
[[3]]
[[4]]
Сравнение моделей
Вложенные многоуровневые модели можно сравнивать между собой также, как и обычные, при помощи дисперсионного анализа (anova(model1, model2)). Небольшая деталь состоит в том, что при сравнение моделей нужно обучать их с параметром REML = F. Что такое REML можно почитать в статье "A few words about REML" [6].
M0_ml <- lmer(log_radon ~ floor + (1 | county), data=radon, REML = F) M2_ml <- lmer(log_radon ~ floor + (floor | county), data=radon, REML = F) anova(M0_ml, M2_ml)
| Df | AIC | BIC | logLik | deviance | Chisq | Chi Df | Pr(>Chisq) | |
|---|---|---|---|---|---|---|---|---|
| M0_ml | 4 | 2097.707 | 2117.000 | -1044.853 | 2089.707 | NA | NA | NA |
| M2_ml | 6 | 2099.043 | 2127.982 | -1043.521 | 2087.043 | 2.664119 | 2 | 0.2639332 |
Нельзя сказать, что модель со случайным углом наклона и свободным коэффициентом лучше, чем модель со случайным свободным коэффициентом (0.2639332 > 0.05, AIC(M0_ml) < AIC(M2_ml)).
Обобщённые многоуровневые линейные модели
Многоуровневая логистическая регрессия
Конечно же, можно строить не только многоуровневые линейные регрессионные модели, но и логистические. Это необходимо, когда зависимая переменная принимает только два возможных значения.
log_model = glmer(y_bin ~ x + (1|group), family = binomial(link="logit"))
Многоуровневая логистическая регрессия не сильно отличается от линейной, но необходимо помнить несколько нюансов. Во-первых, ICC для такой модели рассчитывается иначе, не так как для линейной: .
Во-вторых, необходимо помнить, что значения коэффициентов являются натуральным логарифмом отношения шансов (подробнее).
Порядковая регрессия
Если и более экзотические модели, например порядковая логистическая регрессия. Она применяется, когда зависимая переменаая представляет измерена в порядковой шкале, наприме, шкале Лайкерта. Если переменная номинальная, стоит использовать многоуровневую мультиноминальную логистическую регрессию.
library("ordinal") library("foreign") # Download data https://nagornyy.me/datasets/ESS6/ESS6.sav.zip and unpack it. ess_data <- read.spss("ESS6.sav", to.data.frame = T) optftr <- factor(ess_data$optftr, ordered = T) #optftr <- factor(ess_data$optftr, levels=rev(levels(ess_data$optftr)), ordered=T) ordered_log <- clmm(optftr ~ agea + (1|cntry), ess_data, link = "logit", threshold = "equidistant") summary(ordered_log)
Всё это работает крайне долго, так что я бы не рисковал запускать это будучи на паре.
Коэффициенты в этой модели интерпретируются почти так же, как и для бинарной логистической регрессии, за исключением того, что вместо опоры на одну базовую категорию, мы противопоставляем каждую категорию всем предыдущим. Коэффициенты этой модели следует интерпретировать как логарифм шансов, что Y относится к данной категории и всем предыдущим, а не к тем, что выше.
Самостоятельная
Ваша задача — проанализировать результаты European Social Survey шестой волны или World Values Survey. ESS — это сравнительное межстрановое трендовое исследование установок, взглядов, ценностей и поведения населения Европы, которое проводится почти во всех европейских странах каждые два года, начиная с 2002, методом опроса населения 15 лет и старше по случайной репрезентативной выборке населения в каждой стране с помощью личных интервью на дому у респондентов. WVS — тоже весьма похожий исследовательский проект, объединяющий социологов по всему миру, которые изучают ценности и их воздействие на социальную и культурную жизнь. WVS провёл социологические исследования уже в 97 странах.
Продемонструйте навыки использования многомерной регресси на этих данных:
- определите зависимую и независимые переменные;
- определите переменные индивидуального и группового уровня;
- рассчитайте ICC и решите, нужна ли в вашем случае многоуровневость;
- если многоуровневость нужна, постройте регрессионную модель с разными случайными коэффициентами и выберете лучшую;
- визуализируйте эффекты модели и дайте им интерпретацию.
Описание всех переменных из ESS доступно в протоколе исследования, сами данные можно скачать по ссылке. Для переменных из WVS также есть описание на сайте (раздел "Questionnaire") и данные.
library("foreign") ess = read.spss("ESS6.sav", use.value.labels = T, to.data.frame=T) wws = read.spss("WV6_Data_spss_v_2015_04_18.sav", use.value.labels = T, to.data.frame=T)
Литература
- Gary W. Oehlert. (2011). A few words about REML. http://users.stat.umn.edu/~gary/classes/5303/handouts/REML.pdf
Комментарии