Анализ социальных графов
Введение
Граф — абстрактный математический объект, представляющий собой множество вершин графа и набор рёбер, то есть соединений между парами вершин (их ещё называют узлами). Например, за множество вершин можно взять множество аэропортов, обслуживаемых некоторой авиакомпанией, а за множество рёбер взять регулярные рейсы этой авиакомпании между городами.
Сегодня мы будем говорить в основном о социальных графах — это такие же графы, только узлами или вершинами в них являются социальные акторы. Ребрами графа в этом случае всё так же остаются различные отношения и взаимодействия между узлами. Основной книгой по анализу социальных графов десятилетиями являлась книга «Social Network Analysis: Methods and Applications», вышедшая аж 1994 году [1]. Сейчас она, конечно, уже устарела, но при изучении основ межно опираться на неё.
Социальные графы — очень мощный аналитический инструмент. Благодаря им можно получить уникальную информацию, например, о неформальной структуре организации.
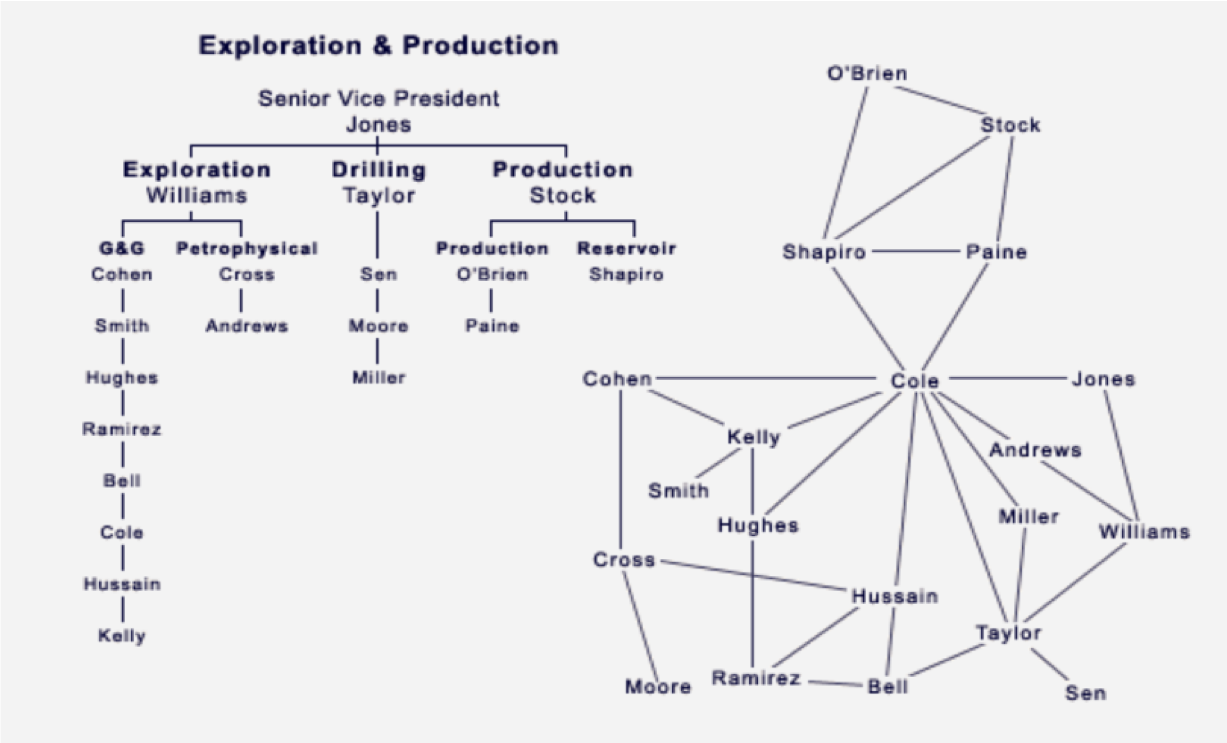
Эгосети
Эгосеть — это сумма связей одного человека. Существует число Данбара — постоянное число стабильных социальных связей, которое способен поддерживать человек. Он проанализировал размер групп и размер неокортекса (отношение коры к остальному мозгу) 38 родов приматов и, экстраполируя результат на род Homo sapience, обнаружил, что для человеческий мозг может поддерживать до 150 связей (доверит. интервал от 70 до 230) [2].
Это число может быть обнаружено везде: размер деревни в примитивных обществах; армейские подразделения (рота, батарея, эскадрон – от 70 до 250); размер компании, которая может управляться без формальной менеджериальной структуры. В Швеции на основании результатов Данбара было принято решение преобразовать налоговое управление таким образом, чтобы в каждом подразделении было не более 150 сотрудников.
Размер персональной социальной сети человека ограничивают следующие факторы:
- Cognitive challenge -- необходимо хранить в памяти большой объем информации;
- Social grooming требует времени.
Посчитать эгосеть человека можно несколькими способами. Первый метод — экстраполяция (scale up). Если:
- – размер популяции;
- – размер личной сети человека;
- -- размер группы в популяции;
- – число людей из этой группы в личной сети человека, то
Вопросы для определения размера личной сети методом scale up: Назовите, сколько среди ваших знакомых (тех, кого вы знаете по имени и имели какой-то контакт за последние 2 года):
- людей мо имени Роберт?
- По имени Николь?
- По имени Дженнифер?
- Диабетиков?
- ВИЧ-положительных?
- Индейцев?
- Пилотов коммерческих авиалиний?
- Почтальонов?
- Родивших ребенка за прошедших год?
- Усыновивших ребенка за прошедший год?
- Сидящих в тюрьме?
- Погибших в автокатастрофе за прошедший год? (всего 29 вопросов о субпопуляциях известного размера)
Пользуясь этим методом, можно вычислить размер скрытой популяции неизвестного размера.
Потенциальные проблемы:
- «barrier effect» — из-за пространственных и социальных (в том числе возрастных) барьеров у разных людей шансы знать представителей той или иной группы неравны.
- «transmission effect» — люди могут не знать всех фактов о своих дальних знакомых.
Другой метод — SUMMATION — представляет собой вопросы о числе людей, с которыми респондент находится в тех или иных отношениях. Типы отношений:
- Ближайшие родственники
- Другие родственники по кров
- Родственники супруга/партнера
- С кем вместе работаешь
и т.д. Потом просто суммируем.
Социальный капитал
Социальный капитал — понятие, введенное Пьером Бурдьё в 1980 году для обозначения социальных связей, которые могут выступать ресурсом получения выгод. В концепции Пьера Бурдьё социальный капитал является исключительно групповым ресурсом. Ценность социального капитала заключается в возможности снижения транзакционных издержек, что в конечном счете приводит к увеличению прибыли организации. Поддерживая «взаимно выгодные» условия, то есть постоянно увеличивая общий социальный капитал, члены группы укрепляют связи между друг другом и одновременно становятся в некотором смысле богаче.
...the aggregate of the actual or potential resources which are linked to possession of a durable network of more or less institutionalized relationships of mutual acquaintance and recognition
Джеймс Коулман в своей статье «Социальный капитал в производстве человеческого капитала» (1988) предложил обновленную концепцию. Согласно ей, социальный капитал является общественным благом, однако производится индивидами с целью последующего извлечения выгоды. Социальный капитал измеряется не столько в количестве полезных связей, сколько в их качестве. Из этого следует, что наиболее высок социальный капитал в тех группах, где люди больше всего друг другу доверяют.
The concept, "social capital," paralleling the concepts of financial capital, physical capital, and human capital - but embodied in relations among persons. ... Three forms: obligations and expectations, which depend on trustworthiness of the social environment, information-flow capability of the social structure, and norms accompanied by sanctions
Роберт Патнэм предложил новую структуру социального капитала: социальные нормы, социальные связи и доверие. Патнэм измеряет социальный капитал с помощью индивидуальных индикаторов, таких, как интенсивность и сила контактов, членство в общественных объединениях, электоральная активность, удовлетворенность взаимоотношениями, соблюдение норм взаимности, чувство безопасности, доверие к соседям и социальным институтам. Групповые или территориальные показатели получают посредством агрегации индивидуальных.
...the collective value of all 'social networks' and the inclinations that arise from these networks to do things for each other.
В книге «Заставляя демократию работать: гражданские традиции в современной Италии». Сравнивая результаты реформы по децентрализации власти в Италии в 1960-х годах, Патнэм обратил внимание на то, что северные регионы, где люди более социально активны (по показателям явки на выборах, участию в ассоциациях, заинтересованности в местных делах), лучше воспользовались переданными полномочиями, в «пассивных» южных, наоборот, качество управления упало. При этом наблюдается четкая корреляция гражданской вовлеченности с историей — опытом независимости и самоуправления в средние века. С этого момента число научных статей, посвященных социальному капиталу, неуклонно растет.
В книге «Bowling Alone: The Collapse and Revival of American Community» Патнэм на основе количественных данных показывает, как американцы все больше и больше отсоединяемся от семьи, друзей, соседей и демократических структур. Патнэм доказывает, что американцы подписывают меньше петиций, принадлежат к меньшему количеству неформальных организаций, хуже знают своих соседей, реже встречаются с друзьями и даже реже общаются с семьями. И не смотря на то, что в боулинг играет больше американцев, чем когда-либо прежде, они делает это не в лигах, как раньше, а индивидуально.
Патнэм также делает различие между двумя видами социального капитала: Bridging social capital и Bonding social capital. Соединение происходит, когда вы общаетесь с людьми, которые походят на вас: тот же самый возраст, та же самая религия, и так далее. Но чтобы создать мирные общества в разнообразной многоэтнической стране, нужно иметь второй вид социального капитала: Bridging social capital, который состоит в том , что вы взаимодействуете с людьми, которые не походят на вас, как, например, фанаты другой футбольной команды. Патнэм утверждает, что те два вида социального капитала, соединяясь, усиливают друг друга. Следовательно, со снижением одного капитала, неизбежно уменьшается количество другого, и общество в целом становится менее мирным.
Гомофилия в социальных сетях
Одно из свойств сетей - это гомофилия, или склонность похожих людей быть связанными друг с другом. Например, наши друзья, как правило, одного с нами пола, у нас схожее образование, интересы и вкусы. В вычислительных социальных науках для оценки гомофилии широко применяется коэффициент ассортативности, предложенный Марком Ньюманом. Он очень прост и элегантен – это коэффициент корреляции между характеристиками человека и его друзей. Соответственно, если похожие люди дружат – то коэффициент ассортативности ближе к 1. Если непохожие люди дружат, то ассортативность будет стремиться к -1.
Механизмы, обеспечивающие гомофилию:
- Селекция – выбирают похожих на себя;
- Социальное влияние (социальное заражение) – люди, которые близко общаются, усваивают привычки, интересы, вкусы и мнения друг друга.
Для исследования этих явлений необходимо сравнивать данные за разные промежутки времени. Это можно сделать, например, с помощью программы SIENA.
Самое известное исследование такого рода называется Framingham Heart Study (на русском). Было выявлено, что на у тех, кто дружит с полными людьми, выше шанс пополнеть [3], а те — кто дружит со счастливыми, сами будут более счастливыми [4].
Форматы хранения графов
Хороший обзор форматов сделала Софья Докука в статье В чем хранить сети? Немного о форматах сетевых данных, поэтому просто сошлюсь на него.
Создание графов в Python
Для работы с графами в Python существует библиотеки networkx и python-igraph. Первая из них целиком написана на Python, имеет очень приятный интерфейс, достаточно богатый набор функци, но не очень хорошо справляется с большими графами. Вторая представляет собой интерфейс к написанной на низкоуровневом языке С программе igraph, а потому работает быстрее, но пользоваться ей не так удобно.
И всё-таки наиболее функциональные библиотеки для работы с социальными графами обитают в мире R. Там, например, можно найти замечательные пареты для создания Exponential random graph models [5], выбор которых в Python значительно скуднее.
Но давайте начнём с самых простых вещей, а именно, посмотрим, как работать с графами при помощи библиотеки networkx. Для этого импортируем её и инструменты визуализации:
import networkx as nx # для визуализации import matplotlib.pyplot as plt %config InlineBackend.figure_format = 'svg' plt.rcParams['figure.figsize'] = (10, 6)
Чтобы создать пустой граф, создим экземпляр класса Graph.
G = nx.Graph()
Затем добавим к этому объекту вершины (пусть это будет четыре человека), передав их список в метод add_nodes_from, и выведем их при помощи метода nodes:
G.add_nodes_from(["Маша", "Саша", "Cергей", "Даша"]) G.nodes()
Сейчас наш граф состоит из четырёх объектов, которые плавают в первозданной бездне. Чтобы получить полноценный граф, необходимо установить связи между парами вершин. Поскольку вершины у нас представлены людьми, эти связи могут быть, например, отношениями родства или коммуникацией.
G.add_edge("Маша", "Саша") G.add_edge("Cергей", "Саша") G.add_edge("Даша", "Саша") G.add_edge("Даша", "Cергей") G.edges()
Можно было добавить все связи за раз и указать дополнительную информацию. Если этот граф отражает коммуникацию между людьми, то мы могли бы добавить информацию о частоте контактов.
G.add_edges_from([("Маша", "Саша", {"freq": 10}), ("Cергей", "Саша", {"freq": 3}), ("Даша", "Саша", {"freq": 5}), ("Даша", "Cергей", {"freq": 6})])
Для доступа к этой информации вызовите метод edges, но уже с аргументом data=True.
G["Cергей"]["Саша"]["freq"] = 22
G.edges(data=True)
Схожим образом можно добавлять мета-информацию и к узлам сети.
G.nodes['Маша']["gender"] = "fem" G.nodes['Даша']["gender"] = "fem" G.nodes['Cергей']["gender"] = "male" G.nodes['Саша']["gender"] = "male"
Визуализация графов
Графы известны тем, что из них получаются красивые визуализации.
Давайте нарисуем и наш граф:
nx.draw(G, with_labels=True, font_weight='bold') plt.show();
Для других типов визуализации, а именно:
- Matrix plot
- Arc plot
- Circos plot
воспользуйтесь пакетом nxviz.
import nxviz as nv nv.MatrixPlot(G).draw()
nv.CircosPlot(G).draw()
nv.ArcPlot(G, node_order="gender", node_color="gender").draw()
Казалось бы, что хорошим примером связи между двумя людим может быть дружба или любовь, но, как мы знаем, эти связи направлены — если Маша любит Сашу, это совсем не значит, что Саша также любит Машу. networkx поддерживает создание направленных графов с помощью класса DiGraph. Давайте создадим смоделируем ситуацию любовного треугольника при помощи направленного графа.
DiG = nx.DiGraph() DiG.add_nodes_from(["Маша", "Саша", "Cергей"]) DiG.add_edge("Маша", "Саша") DiG.add_edge("Cергей", "Маша") nx.draw(DiG, with_labels=True, font_weight='bold') plt.show();
Унимодальные и бимодальные сети
Все сети, о которых говорилось ранее относятся к унимодальным сетям, поскольку их ребра представляют отношения напрямую между однинаковыми акторами. Однако, не менее часто встречается и другой вид сетей — бимодальные. Подробнее о них читайте в блоге Диляры и Софьи. Примером такой сети может быть членство в группах Вконтакте — если два человека состоятв в общей группе, то между ними проводится связь. Как видите, в этой сети есть два типа сущностей — люди и группы.
Меры центральности
- Degree (indegree, outdegree)
- Betweenness
- Closeness
- Eigenvector
Degree centrality
Degree centrality () – это число узлов, непосредственно связанных с данным узлом. В случае для направленных графов выделяют in-degree и out-degree centrality — число входящиъ и исходящий связей. входная степень узла — количество ребер графа, входящих в узел — определяет престиж узла. Выходная степень узла (out-degree) — количество ребер графа, исходящих из узла — определяет влияние узла. Эта характеристика показывает, кто является наиболее активным в сети. Индивидуальный показатель близости к центру показывает, в какой степени узел связан остальными узлами, то есть насколько тесно он связан с группой.
Часто центральность нормализуют на общее количество узлов .
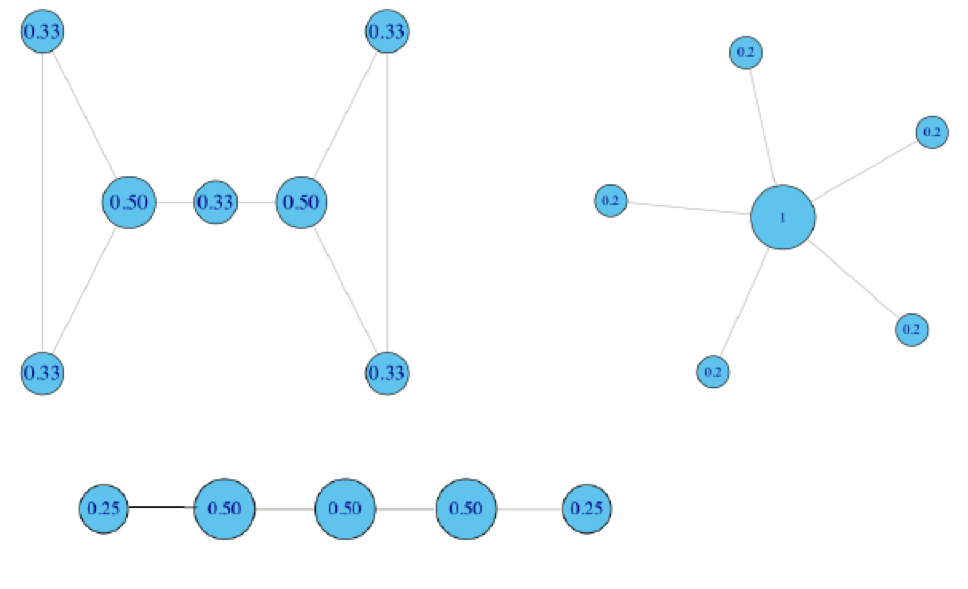
len(G.nodes())
deg_cent = nx.degree_centrality(G) deg_cent
'Саша': 1.0,
'Cергей': 0.6666666666666666,
'Даша': 0.6666666666666666}
[{node: [i for i in G.neighbors(node)]} for node in G.nodes()]
{'Саша': ['Маша', 'Cергей', 'Даша']},
{'Cергей': ['Саша', 'Даша']},
{'Даша': ['Саша', 'Cергей']}]
Centrality – характеристика узла, а можно посчитать ещё Centralization – это характеристика всей сети, которая показывает насколько равномерно распределение Degree centrality. Меры для измерения централизации сети:
- Формула Фримена: , где — максимальное значение центральности в сети.
- Коэффициент Джини
- SD = standard deviation
nx.karate_club_graph(). Сколько в этой сети вершин и ребёр? Найдите две наиболее центральные фигуры клуба и посчитайте центральность сети клубаBetweenness centrality (Центральность по посредничеству)
Центральность по посредничеству (betweenness centrality) — характеризует, насколько важную роль данный узел играет на пути между другими узлами. При анализе футбольного матча центральность по посредничеству позволяет судить, насколько работа с мячом между двумя игроками зависит от третьего игрока. Игроки с высоким уровнем центральности по посредничеству играют ключевые роли в поддержании темпа игры. Эта метрика оценивает участника сети именно в контексте его степени контроля над передачей информации и возможностью контролировать связи между другими ее участниками.
 C_b(i)=\sum_{j<k}\frac{g_{jk}(i)}{g_{jk}}, где – число кратчайших путей между и , – число кратчайших путей между и , проходящих через .
C_b(i)=\sum_{j<k}\frac{g_{jk}(i)}{g_{jk}}, где – число кратчайших путей между и , – число кратчайших путей между и , проходящих через .
Узел с наибольшей Betweenness centrality назвается брокером. Больше о брокерах можно почтать в замечательных статьях блога Asocial Networks.
Closeness centrality (близость к центру)
Мера скорости передачи информации. Как долго будет происходить передача информации от данного узла к другим связанным узлам. Инверсия суммы кратчайших расстояний между каждым узлом и каждым другим узлом в сети. Близость показывает, насколько просто одному узлу связаться с другим узлом. Чем меньше узлов-посредников между текущем узлом и другими узлами, тем ниже показатель близости и выше степень близости.Если узел централен, то он может быстро взаимодействовать с другими узлами.
Измеряется как сумма кратчайших путей от данного узла до всех остальных узлов сети (inverted):
Eigenvector centrality
Важность узла определяется важностью его соседей. Bonancich eigenvector centrality:
где – нормализующая константа, – (attenuation factor) коэффициент «важности» соседей. При получаем просто degree centrality. При маленьких значениях только ближайшие соседи имеют значение. При больших значениях учитываются соседи соседей, соседи соседей соседей и так далее.
Семантические сети
При помощи анализа графов можно также анализировать тексты.
api = '' query = '+russia' import requests url = ('https://newsapi.org/v2/everything?' 'q='+query+ '&sortBy=popularity' '&language=en' '&pageSize=100' '&apiKey='+api) response = requests.get(url) json = response.json()
articles = json['articles'] headline = [article['title'] for article in articles] description = [article['description'] for article in articles] all_text = headline + description from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(ngram_range=(1,2), stop_words = 'english', max_features=200) # You can define your own parameters X = cv.fit_transform(all_text) Xc = (X.T * X) # This is the matrix manipulation step Xc.setdiag(0) # We set the diagonals to be zeroes as it's pointless to be 1 names = cv.get_feature_names() # This are the entity names (i.e. keywords) df = pd.DataFrame(data = Xc.toarray(), columns = names, index = names) df.to_csv('http://nagornyy.me/datasets/gephi_russia_news.csv', sep = ',')
Дальше будем работать в Gephi. Получившийся файл.
Воспроизводство результатов исследования политических блогов в Gephi
Скачайте файл polblogs.gml и прочитайте статью [8]
Кластеризация сетей
Хороший обзор по инструментам кластеризации есть в серии статей Кластеризация графов и поиск сообществ. Для python я бы посоветовал python-louvain
Те, кто заинтересовались, могут пройти курс Network Analysis in Python.
Литература
- Wasserman, S., & Faust, K. (1994). Social Network Analysis: Methods and Applications. Cambridge University Press.
- Dunbar, R. I. M. (1992). Neocortex size as a constraint on group size in primates. Journal of Human Evolution, 22(6), 469–493. https://doi.org/10.1016/0047-2484(92)90081-J
- Christakis, N. A., & Fowler, J. H. (2007). The Spread of Obesity in a Large Social Network over 32 Years. New England Journal of Medicine, 357(4), 370–379. https://doi.org/10.1056/NEJMsa066082
- Fowler, J. H., & Christakis, N. A. (2008). Dynamic spread of happiness in a large social network: longitudinal analysis over 20 years in the Framingham Heart Study. BMJ, 337, a2338. https://doi.org/10.1136/bmj.a2338
- Newman, M. E. J., Watts, D. J., & Strogatz, S. H. (2002). Random graph models of social networks. Proceedings of the National Academy of Sciences, 99(Supplement 1), 2566–2572. https://doi.org/10.1073/pnas.012582999
- Lazega, E., & Snijders, T. A. B. (Eds.). (2016). Multilevel Network Analysis for the Social Sciences: Theory, Methods and Applications. Springer International Publishing. https://www.springer.com/gp/book/9783319245188
- Zachary, W. W. (1977). An Information Flow Model for Conflict and Fission in Small Groups. Journal of Anthropological Research, 33(4), 452–473. https://doi.org/10.1086/jar.33.4.3629752
- Adamic, L. A., & Glance, N. (2005). The political blogosphere and the 2004 U.S. election: divided they blog. 36–43. https://doi.org/10.1145/1134271.1134277
Комментарии